El Kernel¶
Ejecución Directa¶
La ejecución directa de un programa es un concepto simple, significa, correr el programa directamente en la CPU:
El sistema Operativo |
El Programa |
|---|---|
El SO crea un punto de entrada en la lista de Procesos |
|
Reserva memoria para alojar al programa |
|
Carga el Programa en la memoria |
|
Setea el Stack con argv/argc |
|
Limpia los registros |
|
Ejecuta la llamada a main() |
|
Corre main() |
|
Ejecuta return 0 |
|
Libera la memoria reservada |
|
Elimina la entrada en la lista de Procesos |
tiene alguna ventaja la ejecución directa? Si, la rapidez
Pero …. Cuáles son los problemas de este mecanismo tan simple:
Cuando se corre un programa, como se asegura el Sistema Operativo, que el programa no va a hacer nada que el usuario no quiere que sea hecho?
Como hace el sistema Operativo para pausar la ejecución de ese programa y hacer que otro sea ejecutado?
Justamente se necesita Limitar la Ejecución Directa
Limitar la Ejecución Directa¶
Para poder limitar la ejecución directa se necesitan ciertos mecanismos de hardware:
Dual Mode Operation - Modo de operación dual.
Privileged Instructions - Instrucciones Privilegiadas.
Memory Protection - Proteccion de Memoria
Timer Interrupts - Interrupciones por temporizador
Modo Dual de Operaciones¶
El modo de operación dual, es un mecanismo que proveen todas los procesadores y algunos microprocesadores modernos. En un mundo Ideal … el esquema básico de un microprocesador podría ser el siguiente:
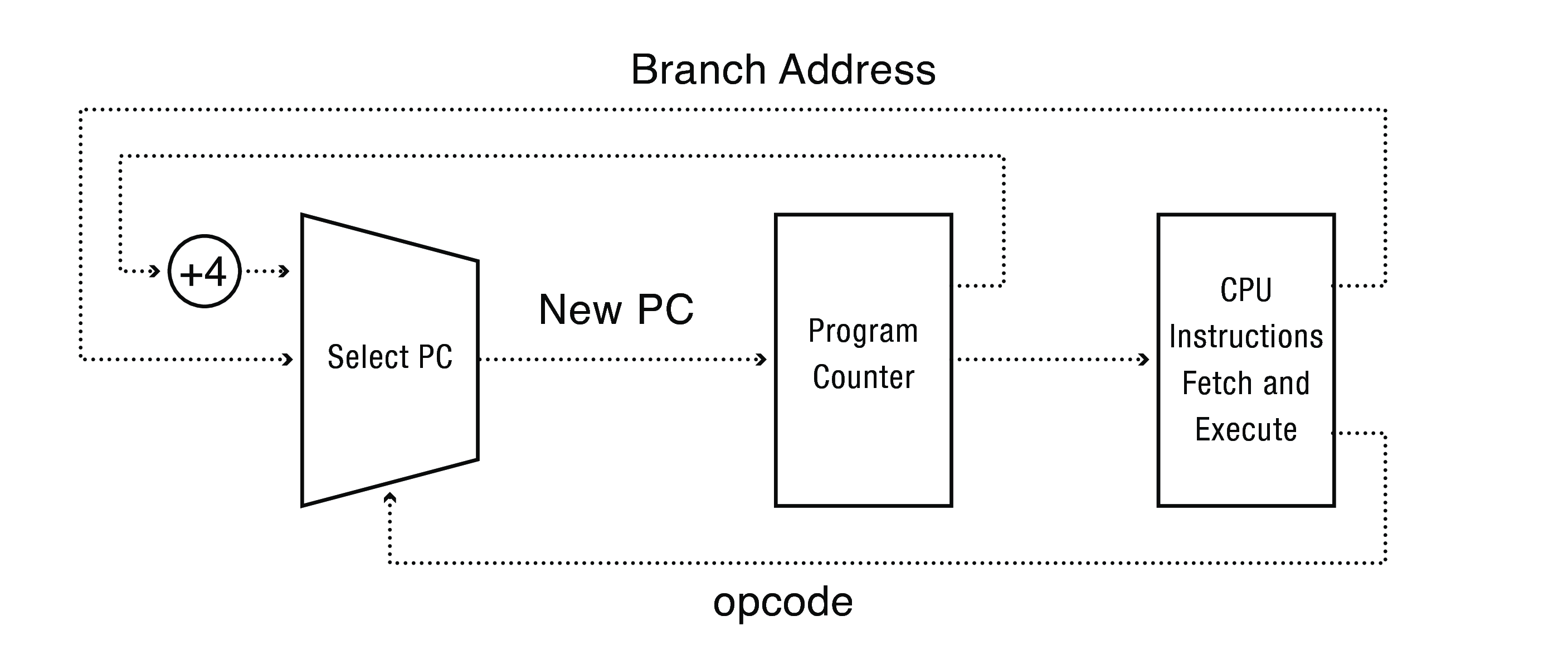
Intel 8088 no tenía bit de modo - no tenía dual mode - (esa es la historia detrás de MSDOS).
La realidad:
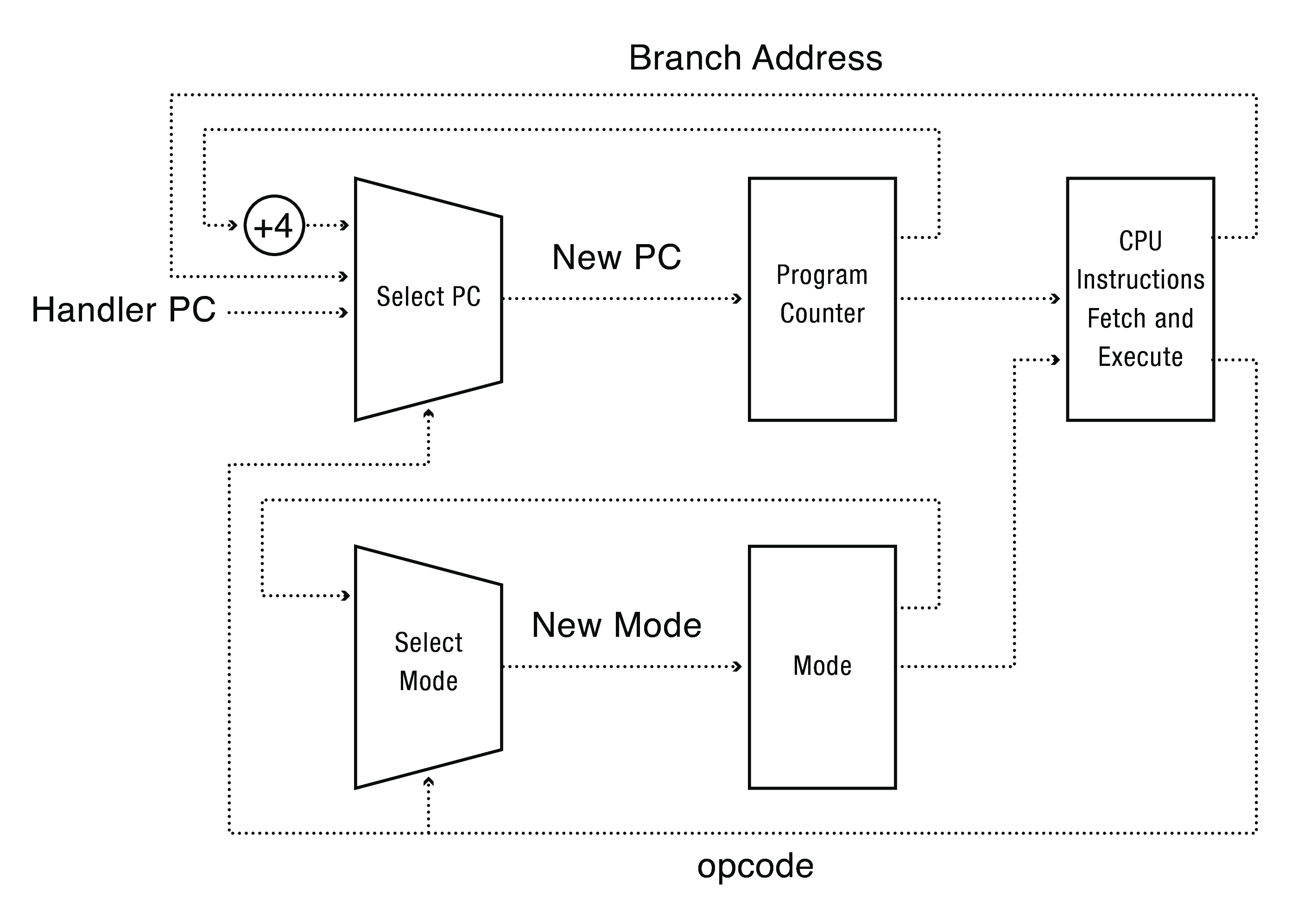
Kernerl Land y User Land¶
Los Modos¶
En el caso de la arquitectura x86 la misma provee 4 modos de operaciones vía el hardware. Estos modos están numerados entre 0 y 3, y se denominan rings.
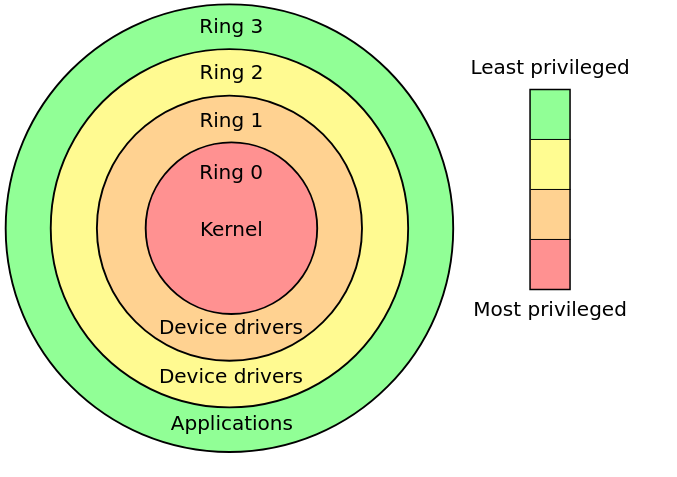
Los modos más utilizados por los sistemas operativos son el modo 0 (modo supervisor o modo Kernel) y el modo 3, llamado modo “Usuario” o “User Mode” dado que este mecanismo es proveído por el hardware cada instrucción a ser ejecutada el mismo chequea en que modo de operación se encuentra.
Existen dos modos operacionales utilizados de la CPU :
Modo Usuario o User Mode: que ejecuta instrucciones en nombre del usuario
Modo Supervisor o Kernel o Monitor: ejecuta instrucciones en nombre del Kernel del S.O. y estas son instrucciones privilegiadas.
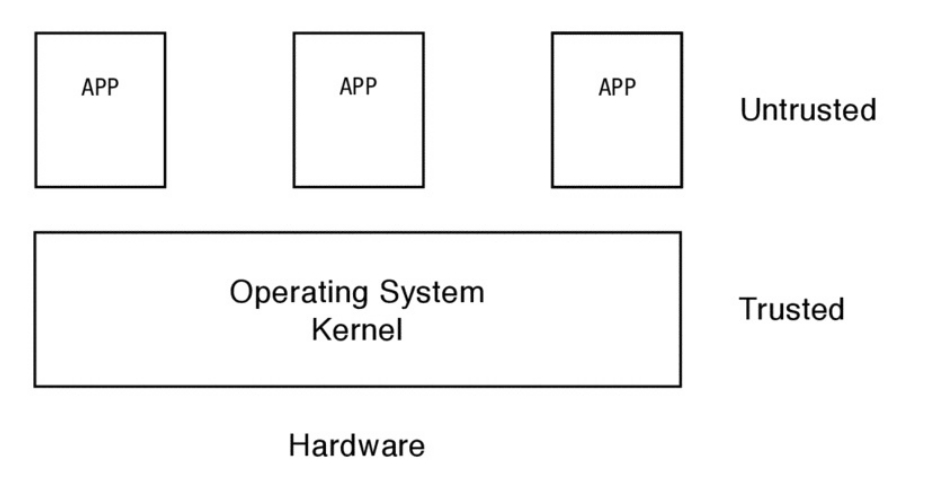
Esta diferencia entre los modos operacionales de un procesador equivale a un bit en el registro de control del procesador. Este bit permite diferenciar entre tipos de instrucciones: instrucciones privilegiadas o instrucciones normales.
A cada uno de estos niveles de privilegio también se lo denominan Ring o Anillo
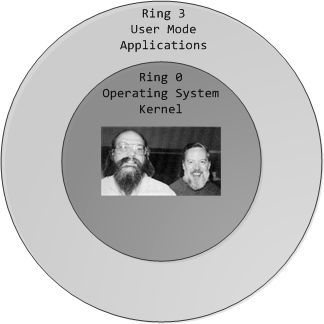
Se protege:
La memoria
Los Puertos de I/O
La Posibilidad de ejecutar ciertas instrucciones
IOPL¶
El indicador IOPL (nivel de privilegio de E / S) es un indicador que se encuentra en todas las CPU x86 compatibles con IA-32. Ocupa los bits 12 y 13 en el registro FLAGS. En modo protegido y modo largo, muestra el nivel de privilegio de E / S del programa o tarea actual. El nivel de privilegio actual (CPL) (CPL0, CPL1, CPL2, CPL3) de la tarea o programa debe ser menor o igual que el IOPL para que la tarea o el programa accedan a los puertos de E / S.

El IOPL se puede cambiar usando POPF (D) e IRET (D) solo cuando el nivel de privilegio actual es Ring 0.
Además de IOPL, los permisos de puerto de E/S en el TSS (Task State Segment) también participan en la determinación de la capacidad de una tarea para acceder a un puerto de E / S.
Protección del Sistema:¶
¿Cual es el hardware necesario para que el kernel del sistema operativo pueda proteger a Usuarios y aplicaciones de otros usuarios ?
Instrucciones Privilegiadas¶
La existencia del mecanismo llamado modo dual permite que los distintos modos posean cada uno su propio set de instrucciones. Con lo cual el bit de modo de operación indica al procesador si la instrucción ejecutada puede ser o no ejecutada, según el modo en que se encuentre el mismo.
Este conjunto de instrucciones sólo puede ser ejecutado en modo kernel
Instrucción |
Descripción |
|---|---|
LGDT |
Loads an address of a GDT into GDTR |
LLDT |
Loads an address of a LDT into LDTR |
LTR |
Loads a Task Register into TR |
MOVCR |
Copy data and store in Control Registers |
LMSW |
Load a new Machine Status WORD |
CLTS |
Clear Task Switch Flag in Control Register CR0 |
MOV |
Debug Register Copy data and store in debug registers |
INVD |
Invalidate Cache without writeback |
INVLPG |
Invalidate TLB Entry |
WBINVD |
Invalidate Cache with writeback |
HLT |
Halt Processor |
RDMSR |
Read Model Specific Registers (MSR) |
WRMSR |
Write Model Specific Registers (MSR) |
RDPMC |
Read Performance Monitoring Counter |
RDTSC |
Read time Stamp Counter |
Estas instrucciones no pueden ser accedidas en user mode
Protección de Memoria¶
El sistema operativo y los programas que están siendo ejecutados por el mismo deben residir ambos en memoria al mismo tiempo.
El sistema operativo tiene que estar ahí para cargar el programa y hacer que comience a ejecutarse.
El programa tiene que residir en memoria para poder ejecutarse, es más todos los programas que se están ejecutando deben estar cargado en la memoria de la máquina.
Debido a esto el y para que la memoria sea compartida de forma segura, el sistema operativo debe poder configurar al hardware de forma tal que cada proceso pueda leer y escribir su propia porción de memoria.
Existen mecanismos de hardware que permiten hacer este control.
Timer Interrupts (Interrupciones por temporizador)¶
Para que el kernel pueda tomar el control de la computadora debe haber algún mecanismo que periódicamente le permita al kernel desalojar al proceso de usuario en ejecución y volver a tomar el control del procesador, y así de toda la máquina.
Cuando un programa se está ejecutando este cree que tiene todo el tiempo del mundo para hacer lo que quiera… pero eso es sólo una ilusión.
En la actualidad todos los procesadores poseen un mecanismo de hardware llamado hardware counter, el cual puede ser seteado para que luego del transcurso de un determinado tiempo el procesador sea interrumpido. Cada CPU posee su propio timer.
Cuando una interrupción por tiempo ocurre, el proceso en modo usuario que se esté ejecutando le transfiere el control al kernel ejecutándose en modo kernel. De esta forma el kernel tiene asegurado el uso del procesador.
Todos los procesadores poseen un dispositivo de hardware llamado Interrupciones de Tiempo. Una Interrupción de Tiempo permite que el procesador sea interrumpido después de un determinado lapso de tiempo. Cada procesador tiene su propio contador de tiempo. Si el procesador es multicore cada core tiene sus propio contador de tiempo individual.
El reseteo del timer es una instrucción privilegiada que puede ser utilizada en modo kernel.
$ cat /proc/timer_list
Visión General¶
Si se define al sistema operativo como el software que maneja y dispone de los recursos de una computadora, entonce el término kernel puede ser equivalente al de sistema operativo.
Viendo al sistema como un conjunto de capas, el sistema operativo se denomina comúnmente kernel del sistema, o simplemente kernel, lo que enfatiza su aislamiento de los programas de los usuarios (sh, vi, wc, ls, etc.).
Gracias a la existencia del kernel los programas son independientes del hardware subyacente, es fácil moverlos entre sistemas UNIX que se ejecutan en hardware diferente dado que los programas no hacen suposiciones sobre el hardware subyacente, sino que se comunican con el kernel y no con el hardware directamente.
El kernel es entonce la capa de software de más bajo nivel en la computadora.
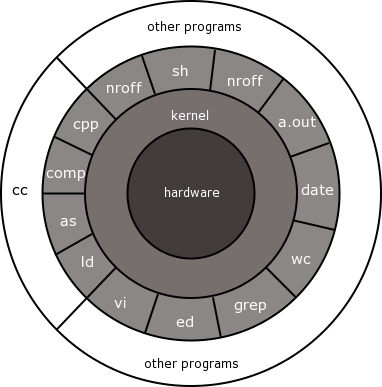
Este contiene por un lado una capa para la gestión de dispositivos específico y por otro una serie de servicios para la gestión de dispositivos agnósticos del hardware que son utilizados por las aplicaciones.
Cuando código fuente de esta capa es ejecutado la computadora pasa a un estado llamado Modo Supervisor.
Un Sistema Operativo puede definirse como el software que controla los recursos de hardware de una computadora y provee un ambiente bajo el cual los programas pueden ejecutarse. Habitualmente a este software se lo llama el Kernel.
Una de las cosas a tener en cuenta es que el kernel es un programa.
Tareas específicas del Kernel¶
Este programa hace cosas, entre ellas:
Planificar la ejecución de las aplicaciones:
Gestionar la Memoria:
Proveer un sistema de archivos:
Creación y finalización de procesos:
Acceder a los dispositivos:
Comunicaciones:
Proveer un API:
Modos de Transferencia¶
Una vez que el hardware posee los mecanismos necesarios para que pueda ejecutarse un kernel tiene que haber una o varias formas de alternar entre modo usuario y modo kernel.
Este tipo de transición no son eventos raros y por ende deben tener un mecanismo que sea seguro y rápido y que además no de lugar para programas maliciosos o con errores que pueden intencionalmente ser inseridos y corromper el Kernel.
De Modo Usuario a Modo Kernel¶
Existen tres formas por las cuales se debería pasar de pasar de modo usuario a modo kernel:
interrupciones,
excepciones del procesador
y mediante la ejecución de system calls (llamadas al sistema).
De hecho estas tres formas representan: por un evento externo (interrupciones) un evento interno inesperado (una excepción) o por un evento intencional generado por una system call (int 0x80).
Interrupciones¶
Una interrupción es una señal asincrónica enviada hacia el procesador de que algún evento externo ha sucedido y pueda requerir de la atención del mismo.
El procesador está continuamente chequeando por si una interrupción se dispara. Si así es, este completa o detiene cualquier instrucción que se esté ejecutando y en vez de ejecutar la siguiente instrucción, el procesador guarda todo el contexto en el que se estaba ejecutando la instrucción y comienza a ejecutar el manejador de esa interrupción en el kernel.
El orden de prioridad de las interrupciones según [BCH], ordenados por prioridad decreciente :
Errores de la Máquina
Timers
Discos
Network devices
Terminales
Interrupciones de Software
Excepciones del Procesador¶
La otra forma por la cual se necesitaría pasar de modo usuario a modo kernel es por un evento de hardware causado por un programa de usuario. El funcionamiento es igual de la una interrupción. Una excepción podría ser:
Acceder fuera de la memoria del proceso
Intentar ejecutar una instrucción privilegiada en modo usuario.
Intentar escribir en memoria de solo lectura.
dividir por cero.
set_trap_gate(0,÷_error);
set_intr_gate(1,&debug);
set_intr_gate(2,&nmi);
set_system_intr_gate(3, &int3); /* int3/4 can be called from all */
set_system_gate(4,&overflow);
set_trap_gate(5,&bounds);
set_trap_gate(6,&invalid_op);
set_trap_gate(7,&device_not_available);
set_task_gate(8,GDT_ENTRY_DOUBLEFAULT_TSS);
set_trap_gate(9,&coprocessor_segment_overrun);
set_trap_gate(10,&invalid_TSS);
set_trap_gate(11,&segment_not_present);
set_trap_gate(12,&stack_segment);
set_trap_gate(13,&general_protection);
set_intr_gate(14,&page_fault);
set_trap_gate(15,&spurious_interrupt_bug);
set_trap_gate(16,&coprocessor_error);
set_trap_gate(17,&alignment_check);
System Calls¶
Las System Calls son funciones que permiten a los procesos de usuario pedirle al kernel que realice operaciones en su nombre. Una System Call es cualquier función que el el kernel expone que puede ser utilizada por un proceso a nivel usuario.
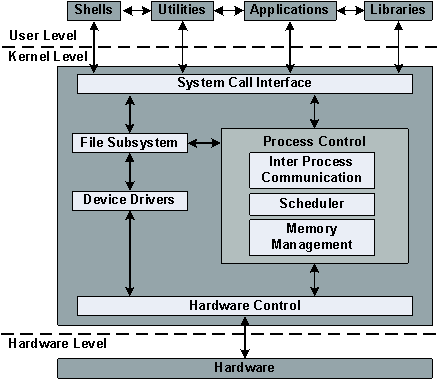
Las System Calls conforman un API
GENERAL CLASS |
SPECIFIC CLASS |
SYSTEM CALL |
|---|---|---|
File Structure Related Calls |
|
|
Calls |
|
|
Interprocess Communication |
|
|
System Call¶
Una system call (llamada al sistema) es un punto de entrada controlado al kernel, permitiendo a un proceso solicitar que el kernel realice alguna operación en su nombre [KER](cap. 3). El kernel expone una gran cantidad de servicios accesibles por un programa vía el application programming interface (API) de system calls.
Algunas características generales de las system calls son:
Una system call cambia el modo del procesador de user mode a kernel mode, por ende la CPU podrá acceder al área protegida del kernel.
El conjunto de system calls es fijo. Cada system call esta identificada por un único número, que por supuesto no es visible al programa, este sólo conoce su nombre.
Cada system call debe tener un conjunto de parámetros que especifican información que debe ser transferida desde el user space al kernel space.
Las system calls de unix v6 syscalls Las system calls de linux para arquitectura x86 syscalls x86
Llamada a una System Call¶
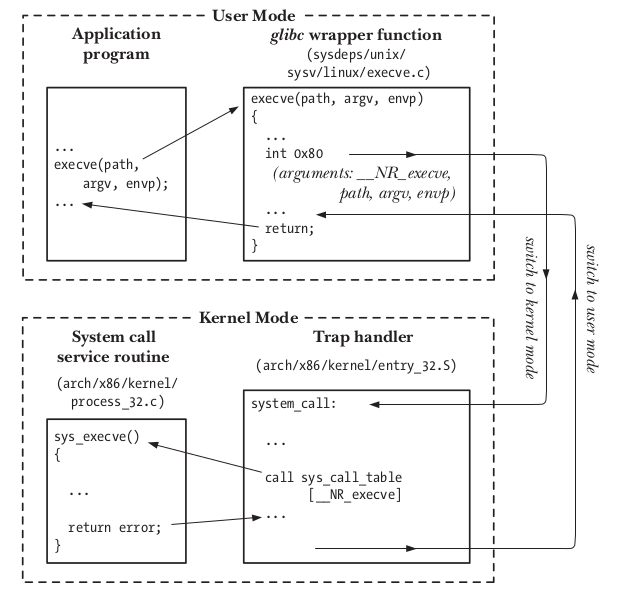
Desde el punto de vista de un programa llamar a una system call es mas o menos como invocar a una función de C. Por supuesto, detrás de bambalinas muchas cosas suceden:
El programa realiza un llamado a una system call mediante la invocación de una función wrapper (envoltorio) en la biblioteca de C.
Dicha función wrapper tiene que proporcionar todos los argumentos al system call trap_handling. Estos argumentos son pasados al wraper por el stack, peeero el kernel los espera en determinados registros. La función wraper copia estos valores a los registros.
Dado que todas las system calls son accedidas de la misma forma, el kernel tiene que saber identificarlas de alguna forma. Para poder hacer esto, la función wrapper copia el número de la system call a un determinado registro de la CPU (%eax).
La función wrapper ejecuta una instrucción de código maquina llamada trap machine instruction (int 0x80), esta causa que el procesador pase de user mode a kernel mode y ejecute el código apuntado por la dirección 0x80 (128) del vector de traps del sistema.
- En respuesta al trap de la posición 128, el kernel invoca su propia función llamada syste_call() (arch/i386/entry.s) para manejar esa trap. Este manejador:
graba el valor de los registros en el stack del kernel.
verifica la validez del numero de system call.
invoca el servicio correspondiente a la system call llamada a través del vector de system calls, el servico realiza su tarea y finalmete le devuelve un resultado de estado a la rutina system_call().
se restauran los registros almacenado en el stack del kernel y se agrega el valor de retorno en el stack.
se devuelve el control al wraper y simultáneamente se pasa a user mode.
Si el valor de retorno del la rutina de servicio de la system call da error, la función wrapper setea el valor en errno.
Pasar de Kernel Mode a User Mode¶
Así como hay varias formas de pasar de modo Usuario a modo Kernel también hay varias formas de pasar de modo kernel a modo usuario:
Un nuevo proceso. Cuando se inicia un nuevo proceso el Kernel copia el programa en la memoria, setea el contador de programa apuntando a la primera instrucción del proceso setea el stack pointer a la base del stack de usuario y switchea a modo usuario.
Continuar despues de una interrupcion una excepcion del procesador o de un system call. Una vez que el Kernel termino de manejar el pedido, este continua con la ejecución de proceso interrumpido mediante la restauración de todos los registros y cambiando el modo a nivel usuario.
Cambio entre diferentes procesos. En algunos casos puede pasar que el Kernel decida ejecutar otro proceso que no sea el que se estaba ejecutando, en este caso el Kernel carga el estado del proceso nuevo a través de la PCB y cambia a modo usuario.
El Sistema Operativo Unix y sus Distintos Sabores¶
Esta es una familia de sistemas operativos no es un único producto, por lo tanto no existe un único kernel.
La importancia de UNIX¶
Unix y sus derivados no son ampliamente conocidos fuera de una comunidad particularmente técnica, pero están en el corazón de de un importante número de sistemas que forman parte de la vida cotidiana de cada uno.
Google, Facebook, Amazon y un gran número de otros servicios están provistos (powered) por Linux, un sistema operativo Unix-like. Así mismo:
Alexa
Una Mac
Android
Los sistemas de navegación en los automóviles
unix tree unix life
UNIX¶
Hacia 1969 Ken Thompson decidió utilizar una PDP-7 que se encontraba en desuso para implementar una versión mínima del sistema operativo llamado MULTICS. No fue hasta el año 1971 que la primera versión de UNIX fue lanzada como proyecto en los laboratorios Bell, de la mano de Dennis Ritchie y Ken Thompson:
UNIX-v1 (Nov. 3, 1971): En su primera edición el sistema operativo ocupaba 16 Kb, 8Kb para programas de usuario, un disco de 512 Kb y un límite de 64 kb por archivo. Escrito en assembler.
UNIX-v2 (Jun. 12, 1972)
UNIX-v3 (Feb. 1973): Versión que tenia un compilador C.
UNIX-v4 (Nov. 1973): Primera versión escrita totalmente en C.
UNIX-v5 (Jun. 1974)
UNIX-v6 (May 1975): Tal vez la versión más conocida por su licencia gratuita para investigación y enseñanza.
UNIX-v7 (Jan. 1979): Versión padre de todos los sistemas operativos basados en UNIX (excepto Coherent, Minix, and Linux).
Reseach Unixes¶
1st Edition (Nov. 3, 1971)¶
First edition of the Unix manual, based on the version that ran on the PDP-11 at the time.
The operating system was two years old, having been ported from the PDP-7 to the PDP-11/20 in 1970.
Includes ar, as, bcd, cal, cat, chdir, chmod, chown, cmp, cp, date, dc, df, du, ed, find, glob, init, ld, ln, ls, mail, mesg, mkdir, mkfs, mount, mv, nm, od, pr, rm, rmdir, roff, sh, sort, stat, strip, su, sum, tty, umount, wc, who, write; also precursors of fsck, reboot, and adb.
The system also had a B and Fortran compiler, a Basic interpreter, device files and functions for managing punched tape, DECtape, and RK05 disks.
2nd Edition (Jun. 12, 1972)¶
Total number of installations at the time was 10, “with more expected”, according to the preface of the manual.
Adds echo, exit, login, man, nroff, strip, stty and the first C compiler.
3rd Edition (Feb. 1973)¶
Introduced a C debugger, pipes, crypt, kill, passwd, ps, size, speak, split, uniq, and yacc.
Commands are split between /bin and /usr/bin, requiring a search path (/usr was the mount point for a second hard disk).
Total number of installations was 16.
4th Edition (Nov. 1973)¶
First version written in C.
Also introduced comm, dump, file, grep, nice, nohup, sleep, sync, tr, wait, and pri|ntf(3). Included a SNOBOL interpreter.
Number of installations was listed as “above 20”.
The manual was formatted with troff for the first time.
Version described in Thompson and Ritchie’s CACM paper,the first public exposition of the operating system.
5th Edition (Jun. 1974)¶
Widely licensed to educational institutions.
Introduced col, dd, diff, eqn, lpr, pwd, spell, tee, and the sticky bit.
Targeted the PDP-11/40 and other 11 models with 18 bit addresses. Installations “above 50”.
6th Edition (May 1975)¶
Includes ratfor, bc, chgrp, cron, newgrp, ptrace(2), tbl, units, and wall.
First version widely available outside of Bell Laboratories, licensed to commercial users, and to be ported to non-PDP hardware (Interdata 7/32).
May 1977 saw the release of MINI-UNIX, a “cut down” v6 for the low-end PDP-11/10.
7th Edition (Jan. 1979)¶
Includes the Bourne shell, ioctl(2), stdio(3), and pcc augmenting the Dennis Ritchie’s C compiler.
Adds adb, at, awk, banner, basename, cu, diff3, expr, f77, factor, fortune, iostat, join, lex, lint, look, m4, make, rev, sed, tabs, tail, tar, test, touch, true, false, tsort, uucp, uux.
The ancestor of UNIX System III and the last release of Research Unix to see widespread external distributions.
Merged most of the utilities of PWB/UNIX with an extensively modified kernel with almost 80% more lines of code than V6. Ported to PDP-11, Interdata 8/32 and VAX (UNIX/32V). 32V was the basis for 3BSD.
8th Edition (Feb. 1985)¶
A modified 4.1cBSD for the VAX, with a System V shell and sockets replaced by Streams.
Used internally, and only licensed for educational use.
Adds Berkeley DB, curses(3), cflow, clear, compress, cpio, cut, ksh, last, netstat, netnews, seq, telnet, tset, ul, vi, vmstat.
The Blit graphics terminal became the primary user interface.
Includes Lisp, Pascal and Altran.
Added a network file system that allowed accessing remote computers’ files as /n/hostname/path, and a regular expression library that introduced an API later mimicked by Henry Spencer’s reimplementation.
First version with no assembly in the documentation.
9th Edition (Sep. 1986)¶
Incorporated code from 4.3BSD; used internally.
Featured a generalized version of the Streams IPC mechanism introduced in V8.
The mount system call was extended to connect a stream to a file, the other end of which could be connected to a (user-level) program. This mechanism was used to implement network connection code in user space.
Other innovations include Sam. According to Dennis Ritchie, V9 and V10 were “conceptual” manuals existed, but no OS distributions “in complete and coherent form”.
10th Edition (Oct. 1989)¶
Last Research Unix.
Although the manual was published outside of AT&T by Saunders College Publishing,there was no full distribution of the system itself.
Novelties included graphics typesetting tools designed to work with troff, a C interpreter, animation programs, and several tools later found in Plan 9: the Mk build tool and the rc shell. V10 was also the basis for Doug McIlroy and James A. Reeds’ multilevel-secure operating system IX.
Plan 9 (1996)¶
Bell Laboratories was disbanded after the release of Plan 9.
Linux¶
En el caso de linux y contrariamente a lo que la mayoría de los usuarios creen, linux no es un sistema operativo sino que Linus desarrolló solo un kernel. El resto de los componentes de linux son desarrollos de terceros como por ejemplo GNU.
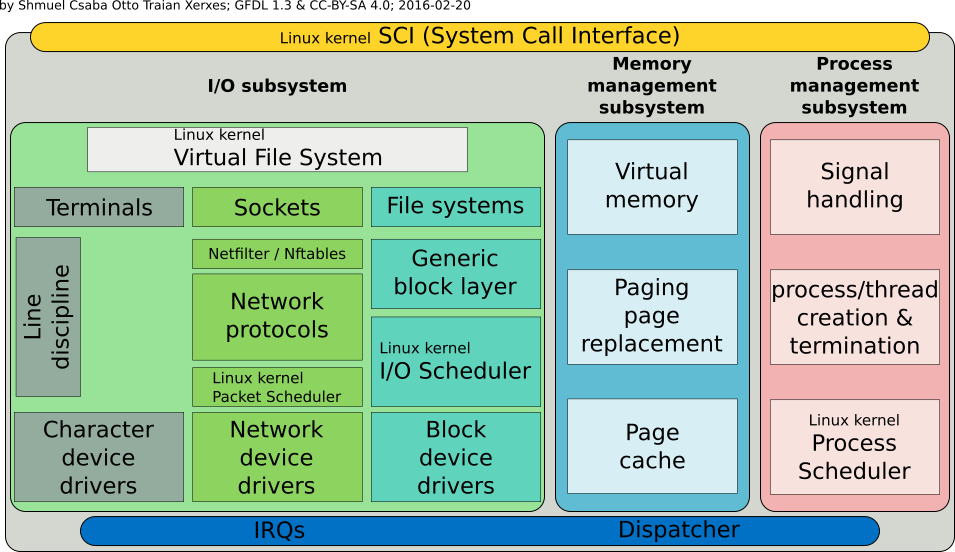
Los fuentes del kernel de linux están disponibles en el repositorio de Linus Trovals <https://github.com/torvalds/linux.git>_. Y pueden ser descargados al propio equipo de la siguiente forma:
`console
$ git clone https://github.com/torvalds/linux.git
$ git pull
`
Directorio |
Descripción |
|---|---|
arch |
Architecture-specific source |
block |
Block I/O layer |
crypto |
Crypto API |
Documentation |
Kernel source documentation |
drivers |
Device drivers |
firmware |
Device firmware needed to use certain drivers |
fs |
The VFS and the individual filesystems |
include |
Kernel headers |
init |
Kernel boot and initialization |
ipc |
Interprocess communication code |
kernel |
Core subsystems, such as the scheduler |
lib |
Helper routines |
mm |
Memory management subsystem and the VM |
net |
Networking subsystem |
samples |
Sample, demonstrative code |
scripts |
Scripts used to build the kernel |
security |
Linux Security Module |
sound |
Sound subsystem |
usr |
Early user-space code (called initramfs) |
tools |
Tools helpful for developing Linux |
virt |
Virtualization infrastructure |
El kernel de linux posee ciertas características a la hora de ser comparado con otros programas:
El kernel no tiene acceso a la biblioteca C ni a los encabezados C estándar.
El kernel está codificado en GNU C.
El kernel carece de la protección de memoria internamente, no se proteje de sí mismo [^4].
El kernel no puede ejecutar fácilmente operaciones de punto flotante.
El kernel tiene una pequeña pila de tamaño fijo y no es dinámica [^5].
Debido a que el kernel tiene interrupciones sincrónicas, es preentive y admite SMP[^6],la sincronización y la concurrencia son preocupaciones importantes dentro del kernel.
La portabilidad es importante.
El kernel de linux posee es un único programa ejecutandose en la memoria de la computador. Para tener una idea la versión 3.0 del kernel de linux liberada el 27 de julio de 2012, comprendia unos 37.792 archivos por un total de 19.688.408 Lineas de Código Fuente que ocupaban uno 460,8 MB de memoria. Este tipo de kernel se denomina Kernel Monolítico.
Desde sus inicios el kernel de linux tuvo su propio modelo de liberación (release-mode). Desde la versión 1.0 los desarrolladores del kernel de linux adoptaron la siguiente nomenclatura x.y.z:x donde x es la versión mayor (mayor versión), y es la versión menor (minor version) dentro de la versión mayor y finalmente z es la revisión dentro de la versión menor. El último valor es opcional e indica la versión estable ( numero par es estable, impar es desarrollo).

MINIX¶
MINIX es un sistema operativo de la familia de UNIX, creado por Andrew S.Tanenbaum con fines didácticos para su curso de sistemas Operativos de la Universidad Libre de Amsterdam. Este venía distribuido en dikettes junto a su libro de texto Operating Systems: Design and Implementation (1987). Versiones de MINIX:
MINIX 1.0 (1987)
MINIX 2.0 (1997)
MINIX 3.0 (2005)
El Kernel de MINIX utiliza una filosofía distinta que el kernel de Linux o de un UNIX tradicional. El kernel se basa en el concepto de microkernel pequeño que maneja interrupciones, gestión de procesos de bajo nivel e IPC, y no mucho más (unas 4000 líneas de código fuente). La mayor parte del sistema operativo se ejecuta como una colección de procesos en modo de usuario.
El concepto clave aquí es el “sistema operativo multiservidor”: el diseño del sistema como un colección de controladores y servidores en modo de usuario con modos de falla independientes.
Mientras el término “microkernel” llama mucho la atención, éstos son ampliamente utilizados en teléfonos celulares, aviónica, automotriz y otros sistemas integrados donde la fiabilidad es crucial.
El microkernel se ejecuta en modo kernel, pero casi todos los demás componentes del sistema operativo se ejecutan en modo de usuario. La capa más baja de procesos en modo de usuario consiste en el dispositivo de E/S controladores, cada conductor completamente aislado en un proceso separado protegido por la MMU y comunicarse con el núcleo a través de una API simple y con otros procesos de paso de mensajes. La siguiente capa está compuesta por servidores, incluido el archivo virtual servidor, el servidor de archivos MINIX, el administrador de procesos, el administrador de memoria virtual, y el servidor de reencarnación. Sobre esta capa están los procesos normales de usuario, tales como X11, shells y programas de aplicación.
BSD¶
Tipos de Kernel¶
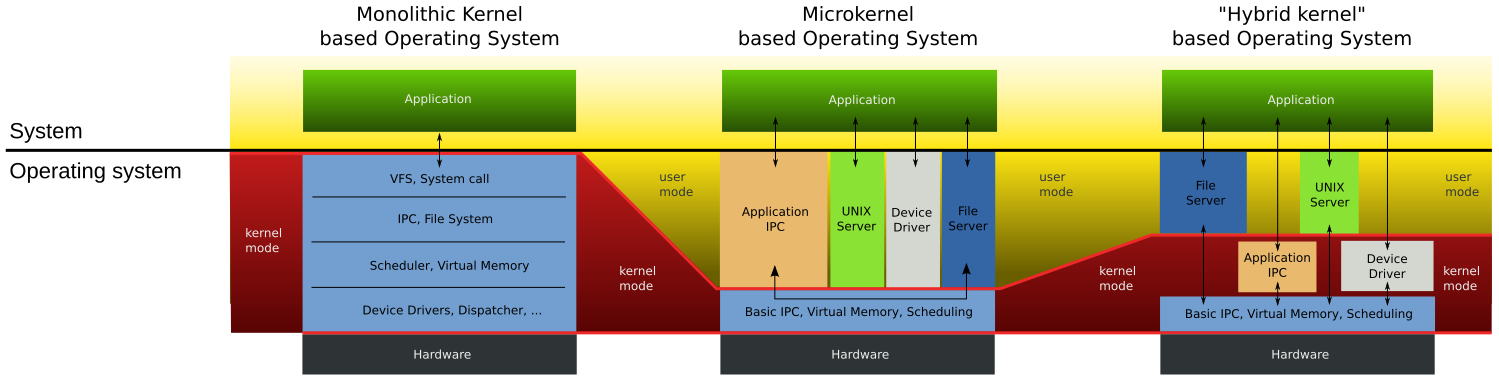
Existen básicamente dos tipos de estructuras de kernel:
Kernel Monolítico: El kernel es un único programa (en realidad proceso) que se ejecuta continuamente en la memoria de la computadora intercambiándose con la ejecución de los procesos de usuario.
Micro Kernel: el kernel sigue existiendo pero sólo implementa funcionalidad básica en el ring 0. Otros servicios se implementan en ring 1 o ring 2, estos servicios no son imprescindibles que se ejecuten en modo kernel exclusivamente.
Más Sobre el Kernel¶
Según VAHALIA, Uresh en su libro “UNIX internals: the new frontiers” de editorial Pearson Education India, 2008:
Implementa el Modelo de Procesos y otros servicios del sistema.
Reside en el disco en un archivo típicamente llamado /vmlinuz, /vmunix o /unix (dependiendo del vendedor de UNIX).
Cuando el sistema se inicia, éste carga al Kernel desde el disco usando un procedimiento especial llamado bootstrapping.
El Kernel inicializa el sistema y setea el ambiente para correr procesos.
Entonces, el Kernel crea algunos procesos iniciales, los cuales a su vez crean otros procesos.
Una vez cargado en la memoria el Kernel permanece allí hasta que se apague la computadora.
Él administra los procesos y les provee de varios servicios (acceso a disco, acceso a network, acceso a usb, etc).
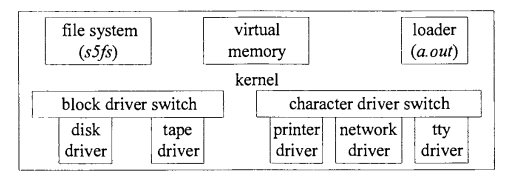
Una versión primitiva del kernel de Unix¶
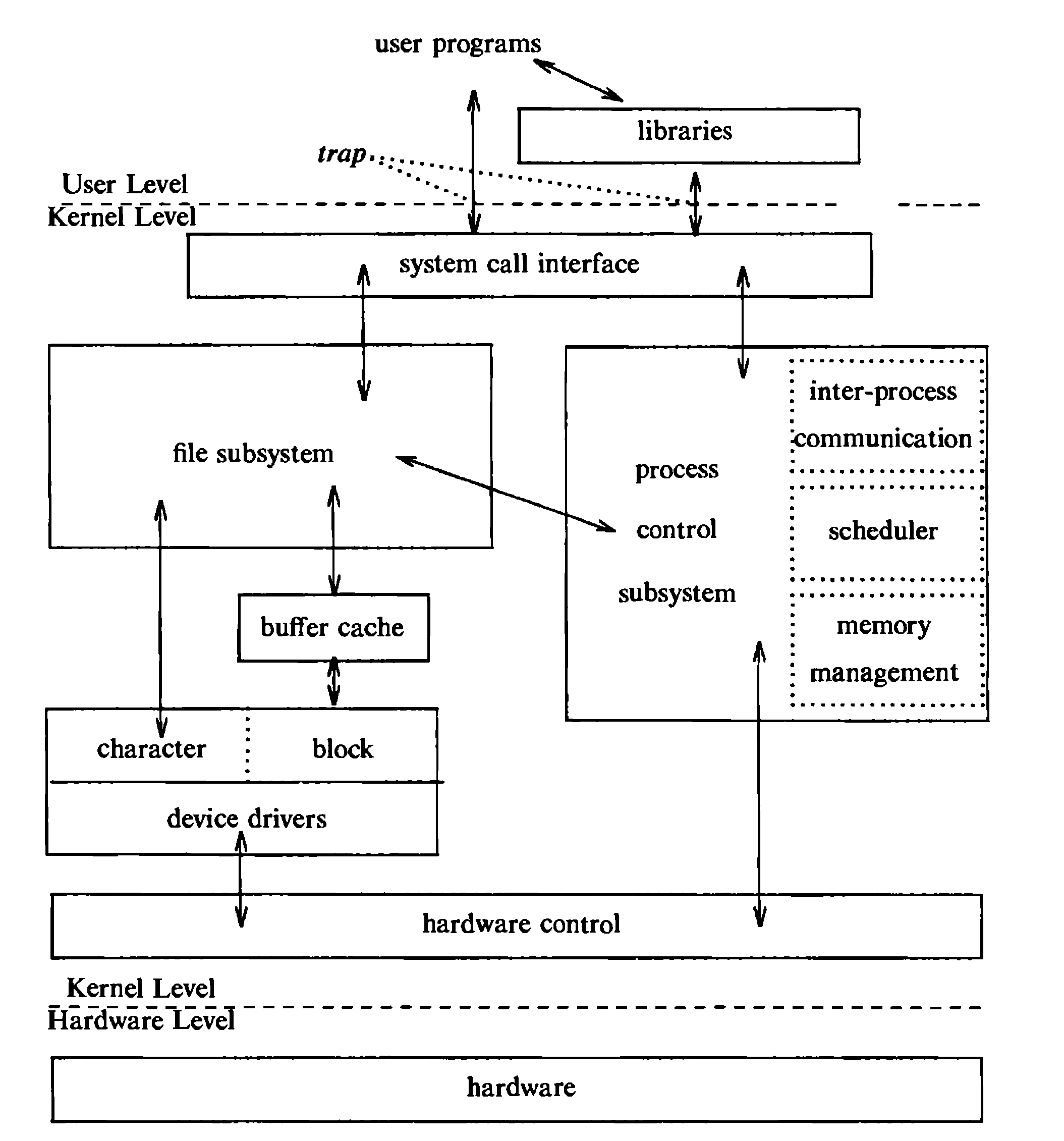
Una versión moderna del Kernel de Unix¶
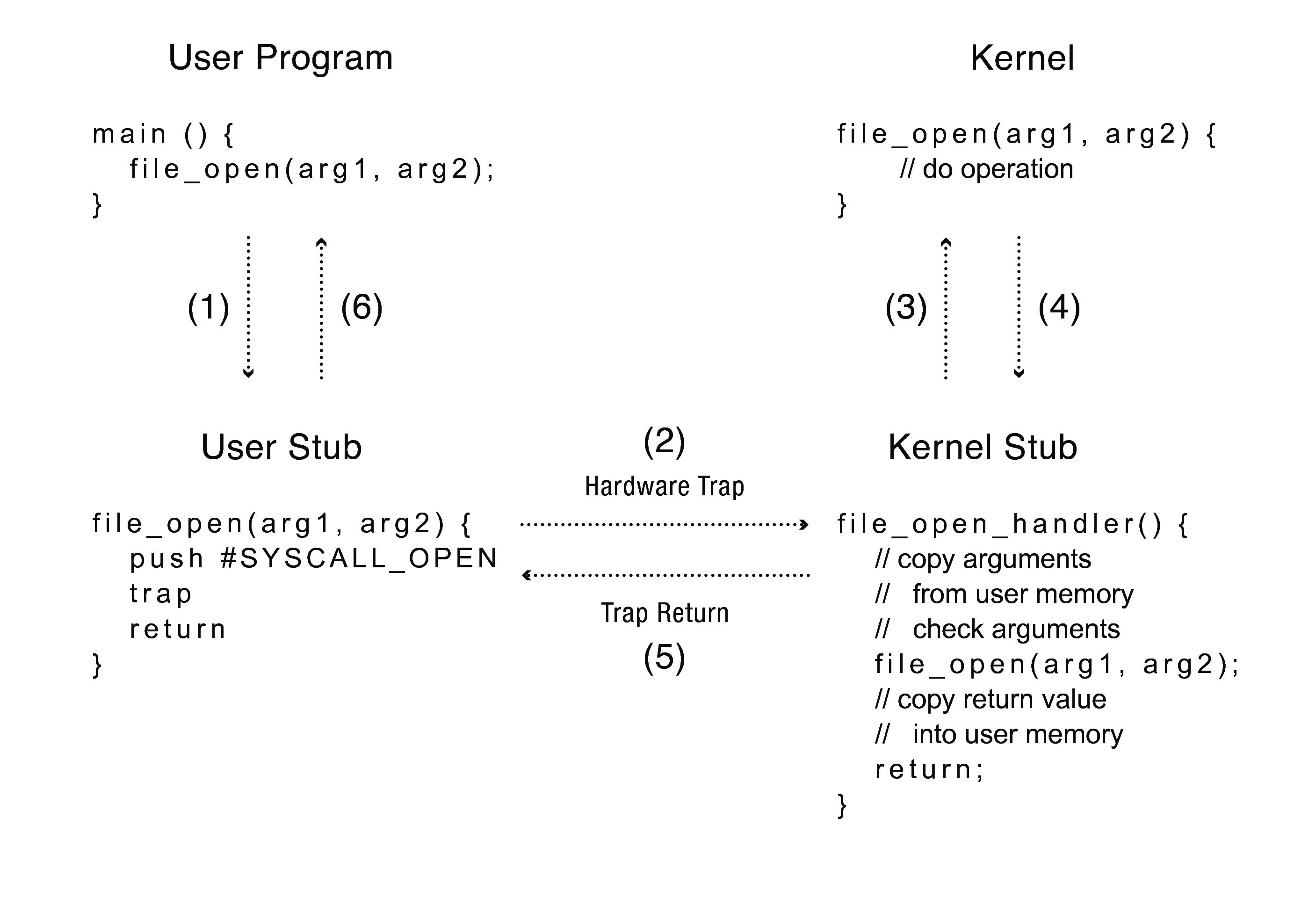
Alguna Funcionalidad que provee el Kernel en el sistema operativo UNIX¶
Los procesos de Usuario explícitamente requieren servicios al Kernel a través del uso de las System Call, que es el componente central del API (Application Programming Interface) de UNIX. El Kernel ejecuta los pedidos en nombre de los procesos que utilizan las System Calls
¿Qué sucede cuando el Kernel falla?¶
Iniciar al Sistema Operativo y el Kernel¶
El kernel es la capa de software de más bajo nivel en la computadora. Este contiene por un lado una capa para la gestión de dispositivos específicos y por otro una serie de servicios para la gestión de dispositivos agnosticos del hardware que son utilizados por las aplicaciones.
Estas dos capas suelen ser conocida como el kernel del sistema operativo. Cuando código fuente de esta capa es ejecutado la computadora pasa a un estado llamado Modo Supervisor.
El proceso de inicio de una computadora se divide esencialmente en 3 partes:
Booteo: este proceso es denominado bootstrap, y generalmente depende del hardware de la computadora. En el se realizan los chequeos de hardware y se carga el bootloader, que es el programa encargado de cargar el Kernel del Sistema Operativo. Este proceso consta de tres partes.
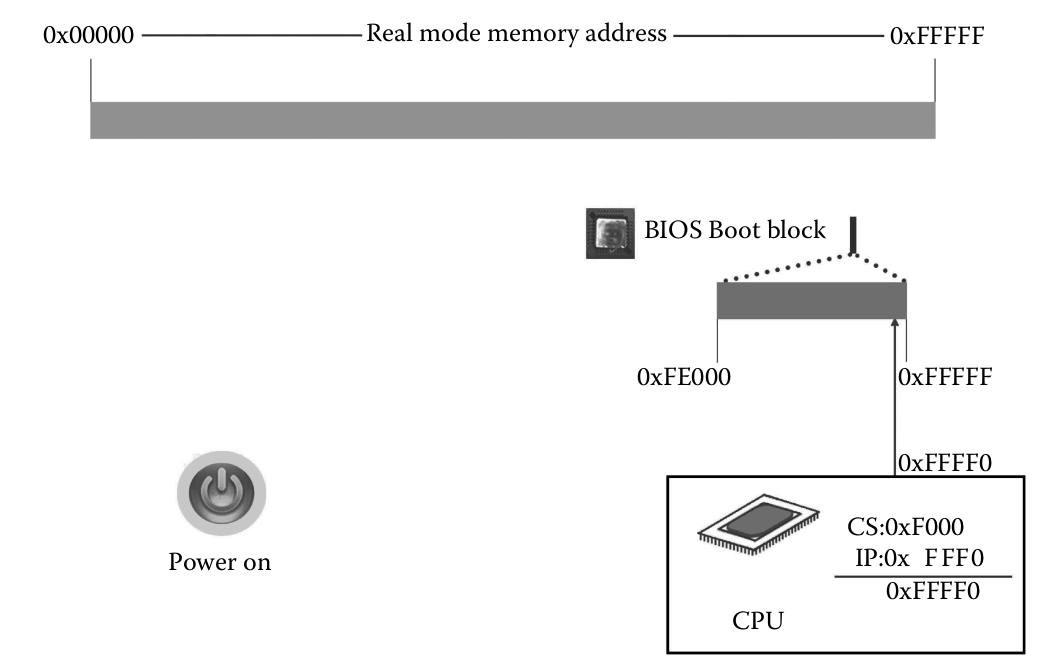
Cargar el BIOS (Basic Input/Output System): para eso apenas se enciende la PC, se carga CS con 0xFFFF y IP con 0x0000; por ende, la dirección de CS:IP es 0xFFFF0, justamente la dirección de memoria de la BIOS.
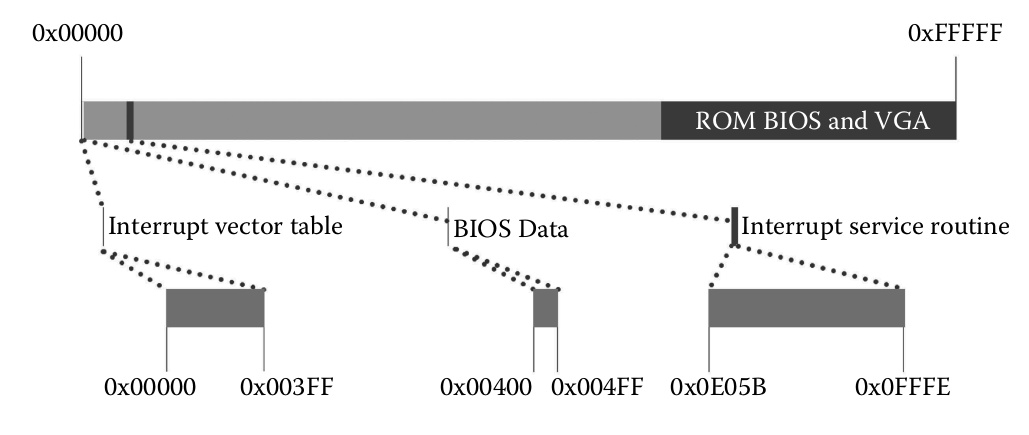
Crear la Interrupt Vector Table y cargar las rutinas de manejo de interrupciones en Modeo Real: el BIOS pone la tabla de interrupciones en el inicio de la memoria 1 KB (0x00000–0x003FF), son 256 entradas de 4 bytes. El área de datos del BIOS de unos 256 B (0x00400–0x004FF), y el servicio de atención de interrupciones (8 KB), 56 KB, después de la dirección 0x0E05B.
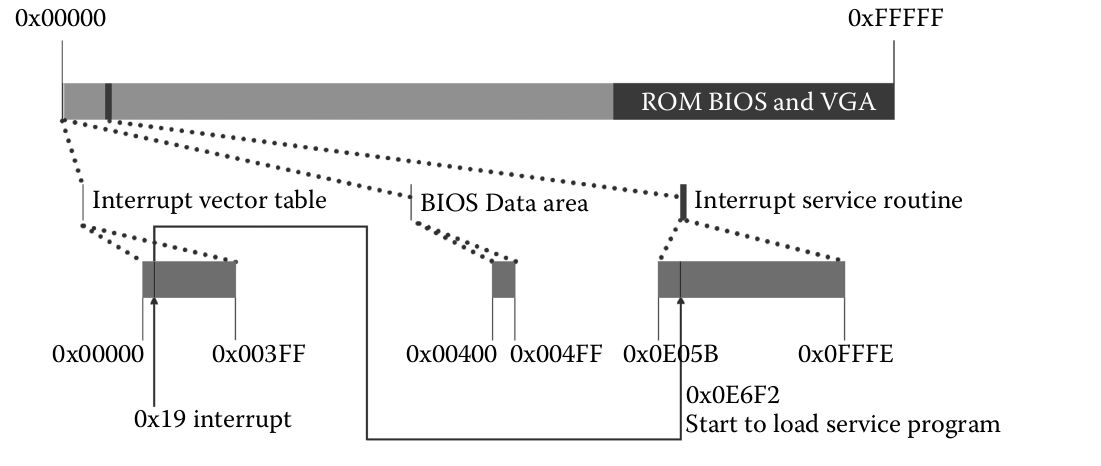
La BIOS genera una interrupción 19 (INT 19) de la tabla de interrupciones la cual hace apuntar a CS:IP a 0x0E6F2.
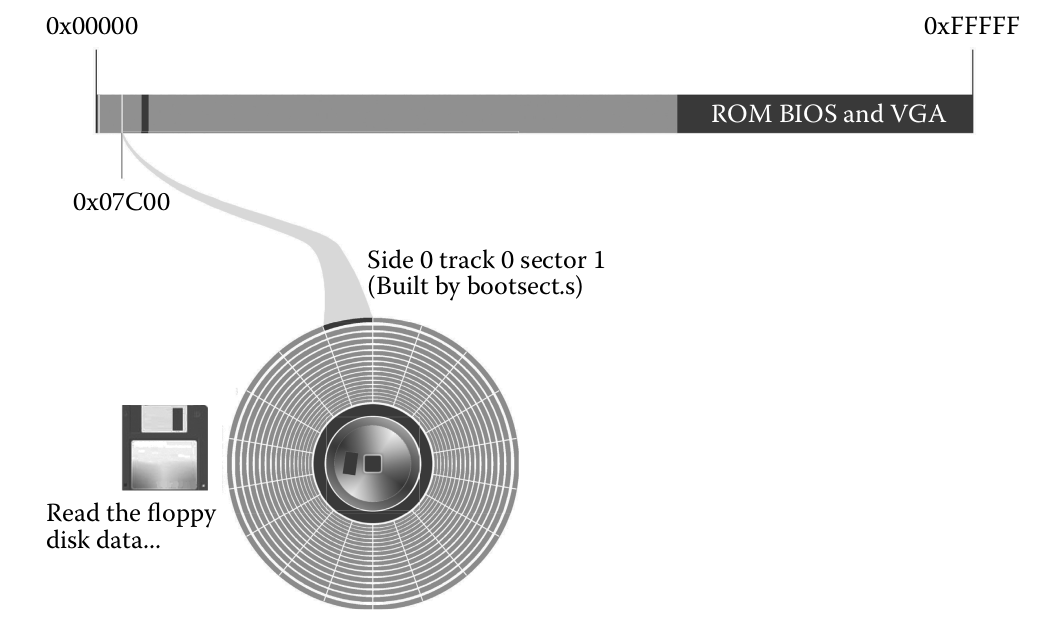
Lo cual hace ejecutar el servicio de interrupciones, el handler de dicha interrupción, que es leer el primer sector de 512 bytes del disco a memoria, y ahí termina.[Paso4](/images/boot/bios4.png)
Carga del Kernel: el BootLoader por el momento de forma más o menos transparente es un programa que se encarga de:
Pasar a Modo Supervisor, esto es posible porque se realiza por hardware
Ir a buscar el kernel al dispositivo donde se encuentra almacenado, normalmente un disco (pero puede ser un pendrive,la red, un CD).
Lo carga en la memoria principal
Setear el registro de PI (Proxima Instruccion)
Ejecutar la primer instrucción del kernel
Inicio de las Aplicaciones de usuarios: Una vez que el Kernel terminó de ejecutarse, las últimas operaciones que realiza son:
Cargar en memoria la aplicación que se debe ejecutar, normalmente este programa es el shell.
Setear el PI en la primera instrucción de esta aplicación.
Pasar a modo Usuario y dejar el control a la aplicación.
En la realidad lo que sucede es:
Fase de Carga del Kernel¶
El kernel es cargado normalmente como un archivo imagen, comprimido dentro de otro con zlib como zImage o bzImage, esto quiere decir que no es un archivo ejecutable normal, se encuentra comprimido en ese formato.
Contiene una cabecera de programa que hace una cantidad mínima de instalación del hardware, descomprime la imagen completamente en la memoria alta, teniendo en cuenta cualquier disco RAM si está configurado (/boot/initrd-2.6.14.2.img).
A continuación, lleva a cabo su ejecución. Esto se realiza llamando la función startup del kernel (en los procesadores x86 a través de la función startup_32() del archivo /arch/i386/boot/head).
Fase de inicio del kernel¶
La función de arranque para el kernel (también llamado intercambiador o proceso 0) establece la gestión de memoria (tablas de paginación y paginación de memoria), detecta el tipo de CPU y cualquier funcionalidad adicional como capacidades de punto flotante, y después cambia a las funcionalidades del kernel para arquitectura no específicas de Linux, a través de una llamada a la función start_kernel().
start_kernel() ejecuta una amplia gama de funciones de inicialización:
Establece el manejo de interrupciones (IRQ)
configura memoria adicional
comienza el proceso de inicialización (procesa el espacio del primer usuario y luego comienza la tarea inactiva a través de cpu_idle().
En particular, el proceso de inicio del kernel también monta el disco RAM inicial (“initrd”) que se ha cargado anteriormente como el sistema raíz temporal durante la fase de arranque.
Esto permite que los módulos controladores se carguen sin depender de otros dispositivos físicos y drivers y mantiene el kernel más pequeño.
El sistema de archivos raíz es cambiado más tarde a través de la llamada a pivot_root(), que desmonta el sistema de archivos temporal y lo reemplaza por el real una vez que éste sea accesible. La memoria utilizada por el sistema de archivos temporal es entonces recuperada.
Por lo tanto, el núcleo inicializa los dispositivos, monta el sistema de archivos raíz especificado por el gestor de arranque como de sólo lectura, y se ejecuta Init (/sbin/init), que es designado como el primer proceso ejecutado por el sistema (PID=1). También puede ejecutar opcionalmente initrd para permitir instalar y cargar dispositivos relacionados (disco RAM o similar), para ser manipulados antes de que el sistema de archivos raíz está montado.
En este punto, con las interrupciones habilitadas, el programador puede tomar el control de la gestión general del sistema, para proporcionar multitarea preventiva, e iniciar el proceso para continuar con la carga del entorno de usuario en el espacio de usuario.
El proceso de inicio¶
El trabajo de Init es “conseguir que todo funcione como debe ser” una vez que el kernel está totalmente en funcionamiento. En esencia, establece y opera todo el espacio de usuario. Esto incluye:
la comprobación y montaje de sistemas de archivos
la puesta en marcha los servicios de usuario necesarios y, en última instancia, cambiar al entorno de usuario cuando el inicio del sistema se ha completado.
Es similar a los procesos Init de Unix y BSD, de la que deriva, pero en algunos casos se ha apartado o se hicieron a la medida.
En un sistema Linux estándar, Init se ejecuta con un parámetro, conocido como nivel de ejecución, que tiene un valor entre 1 y 6, y que determina que subsistemas pueden ser operacionales.
Cada nivel de ejecución tiene sus propios scripts que codifican los diferentes procesos involucrados en la creación o salida del nivel de ejecución determinado, y son estas secuencias de comandos los necesarios en el proceso de arranque. Los scripts de Init se localizan normalmente en directorios con nombres como “/etc/rc…”.
El archivo de configuración de más alto nivel para Init es /etc/inittab.
Durante el arranque del sistema, se verifica si existe un nivel de ejecución predeterminado en el archivo /etc/inittab, si no, se debe introducir por medio de la consola del sistema. Después se procede a ejecutar todos los scripts relativos al nivel de ejecución especificado.
Después de que se han dado lugar todos los procesos especificados, Init se aletarga, y espera a que uno de estos tres eventos sucedan:
que procesos comenzados finalicen o mueran;
un fallo de la señal de potencia (energía);
o una petición a través de /sbin/telinit para cambiar el nivel de ejecución.
Habitualmente en una instalación desktop se ejecuta comúnmente /sbin/init