Scheduling o Planificación de Procesos¶
Cuando hay múltiples cosas qué hacer ¿Cómo se elige cuál de ellas hacer primero?
Debe existir algún mecanismo que permita determinar cuanto tiempo de CPU le toca a cada proceso. Ese período de tiempo que el kernel le otorga a un proceso se denomina time slice o time quantum.
Esto sucede en los sistemas operativos de tipo Time Sharing.
Time Sharing¶
Los Sistemas Operativos llamados time sharing surgen de la idea de los programadores de tener “toda una computadora para uno mismo”. Esta idea que en la actualidad puede parecer trivial, pero en la década de los 60’s era algo impensable.
Inicialmente IBM fue la primera empresa en utilizar circuitos integrados para sus computadoras, la linea IBM 360 (https://en.wikipedia.org/wiki/IBM_System/360_Model_20) , y su mayor fortaleza era la idea de tener una sola familia de computadoras.
El sistema operativo que corría en estas máquinas es el conocido OS 360. Esta familia de computadoras introdujo varias técnicas innovadoras en el desarrollo de los sistemas operativos. Una de estas técnicas es la de multiprogramación.


Multiprogramación¶
La idea básica de la multiprogramación es la siguiente: si un determinado programa que se estaba ejecutando debía realizar operaciones de entrada y salida de datos, debía interactuar con un dispositivo de entrada y salida. Esta interacción en términos de tiempos de ejecución de intrucciones del procesador podía parecer infinito. Además, con el agravante de que el tiempo de E/S solía ser en promedio de entre el 80% y 90% del tiempo total del programa, la CPU permanecía inactiva un gran período de tiempo.
Utilización de la CPU¶
Si se asume que el 20% del tiempo de ejecución de un programa es solo cómputo y el 80% son operaciones de entrada y salida, con tener 5 procesos en memoria se estaría utilizando el 100% de la CPU.
Siendo un poco más realista se supone que las operaciones de E/S son bloqueantes (una operación de lectura a disco tarda 10 miliseg y una instrucción registro registro tarda 1-2 nanoseg), es decir, paran el procesamiento hasta que se haya realizado la operación de E/S.
Entonces, el cálculo es más realista si se supone que un proceso gasta una fraccción p, bloqueado en E/S. De esta manera, si tenemos n procesos esperando para hacer operaciones de entrada y salida, la probabilidad de que los n procesos estén haciendo E/S es \(p^n\).
Por ende la probabilidad de que se esté ejecutando algún proceso es \(1-p^n\), esta fórmula es conocida como utilización de CPU.
Por ejemplo: si se tiene un solo proceso en memoria y este tarda un 80% del tiempo en operaciones de E/S el tiempo de utilización de CPU es 1-0.8 = 0.2 que es el 20%.
Ahora bien, si se tienen 3 procesos con la misma propiedad, el grado de utilización de la cpu es \(1-0.8^3\) = 0.488 es decir el 48 de ocupación de la cpu.
Si se supone que se tienen 10 procesos, entonces la fórmula cambia a \(1-0.8^10\) =0.89 el 89% de utilización, aquí es donde se ve la IMPORTANCIA de la Multiprogramación.
Hay que tener en cuenta que estos tiempos varían de proceso en proceso.
Multiple Fixed Partitions¶
1967 - IBM System /360 (OS/MFT)
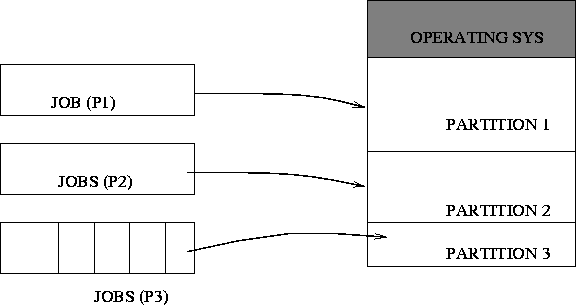
Multitasking with a Fixed number of Tasks _MFT_: varias particiones de memoria, cada una de un tamaño fijo, se establecían cuando el sistema operativo se instalaba o podían ser redefinidas por el operador.
Por ejemplo, podría haber una partición pequeña, dos particiones medianas y una partición grande.
Si había dos programas grandes listos para funcionar, uno tendía que esperar hasta que el otro terminara y desocupara la partición grande.
Cada partición era monoprogramada, la multiprogramación ocurría entre las particiones.
Los límites de las particiones no eran móviles.
Las particiones eran de tamaño fijo.
La fragmentación era un problema.
No existía el concepto de memoria compartida.
Multiple variable Partitions¶
IBM System /360 OS/MVT
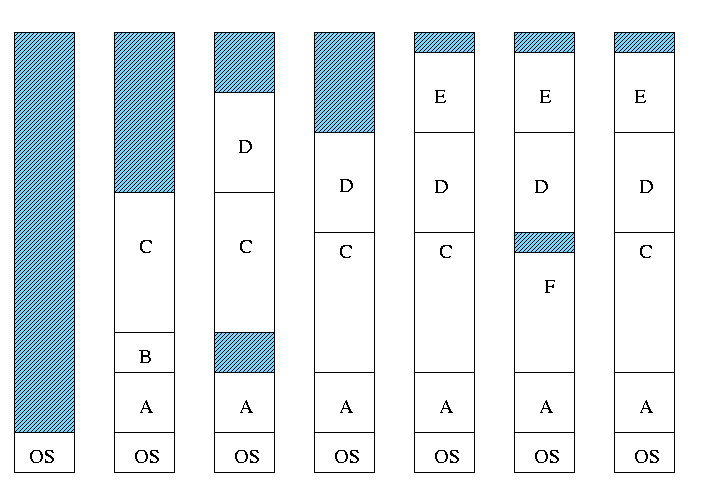
Multitasking with a Variable number of Tasks MVT trataba a toda la memoria no utilizada por el sistema operativo como un único gran espacio desde el cual se podían asignar “regiones” contiguas tanto como lo requiriera un número ilimitado de aplicaciones y programas simultáneamente.
Cada tarea podía tener cualquier tamaño, la limitante era la memoria de la máquina.
Una única cola de procesos listo para correr.
La tarea podía ser movida.
Se elimina la fragmentación interna.
Introduce la fragmentación externa.
¿Qué pasa si ?¶
Imagínese que está en una oficina de correos en la cual solo hay una ventanilla atendiendo, y varias personas haciendo fila para ser atendidas. Solo una persona puede ser atendida a la vez. En el momento que uno es atendido se da cuenta de que no tiene los requisitos necesarios para despachar la carta, aún debe cerrar el sobre, y escribir la dirección del remitente.
Una opción válida es en ese momento cerrar el sobre y terminar de escribir la dirección del remitente, dejando a todas las personas de la fila esperando hasta que se hayan cumplido con lo requisitos y la carta pueda ser despachada. Una vez hecho esto, la próxima persona en la fila podrá despachar su correo.
Otra alternativa es apartarse de la fila, dejar pasar a las personas que cumplan los requisitos para enviar la carta y mientras tanto cerrar el sobre y completar la información del remitente, y una vez realizada esta operación acercarse a la ventanilla y despachar la carta.
En esta última opción esta detrás la idea de multiprogramación. El concepto detrás de este ejemplo en el cual uno es un proceso, la ventanilla es la CPU y la carta representa procesamiento, se basa en cargar simultáneamente varios procesos en la memoria de una computadora y aunque solo uno pueda ser ejecutado a la vez, cuando éste deba interrumpir el procesamiento por algún motivo, por ejemplo operaciones de E/S, otro de los procesos cargados en la memoria de la computadora pueda ser ejecutado, mientras el primero espera por la finalización de la operación que lo detuvo.
Si bien parece trivial el razonamiento, hay que tener en cuenta que una computadora debe poder cargar simultáneamente los programas en diversas partes de la memoria y debe proveer un mecanismo de protección para que los programas no interfieran unos con otros.
Time Sharing¶
Si bien la idea de multitarea agilizó el procesamiento de los procesos, aún las computadoras utilizaban su procesador para ejecutar un único programa a la vez. La noción de tener una computadora para un solo programador era un poco descabellada aún.
A medida que los tiempos de respuesta entre procesos se fueron haciendo cada vez más pequeños, más procesos podían ser cargados en memoria para su ejecución.
Una variante de la técnica de multiprogramación consistió en asignar una terminal a cada usuario en linea.
Teniendo en cuenta que los seres humanos tienen un tiempo de respuesta lento (0.25 seg para estímulos visuales) en comparación a una computadora (operación en nanosegundos). Debido a esta diferencia de tiempos y a que no todos los usuarios necesitan de la cpu al mismo tiempo, este sistema daba la sensación de asignar toda la computadora a un usuario determinado Corbató y otros. Este concepto fue popularizado por MULTICS.
Cuando un Sistema Operativo se dice que realiza multi-programación de varios procesos debe existir una entidad que se encargue de coordinar la forma en que estos se ejecutan, el momento en que estos se ejecutan y el momento en el cual paran de ejecutarse. En un sistema operativo esta tarea es realizada por el Planificador o Scheduler que forma parte del Kernel del Sistema Operativo.
Números y el Workload¶
El Workload es carga de trabajo de un proceso corriendo en el sistema.
Determinar cómo se calcula el workload es fundamental para determinar partes de las políticas de planificación. Cuanto mejor es el cálculo, mejor es la política. Las suposiciones que se harán para el cálculo del workload son más que irreales.
Los supuestos sobre los procesos o jobs que se encuentran en ejecución son:
Cada proceso se ejecuta la misma cantidad de tiempo.
Todos los jobs llegan al mismo tiempo para ser ejecutados.
Una vez que empieza un job sigue hasta completarse.
Todos los jobs usan únicamente cpu.
El tiempo de ejecución (run-time) de cada job es conocido.
Métricas de Planificación¶
Para poder hacer algún tipo de análisis se debe tener algún tipo de métrica estandarizada para comparar las distintas políticas de planificación o scheduling. Bajo estas premisas, por ahora, para que todo sea simple se utilizará una única métrica llamada turnaround time. Que se define como el tiempo en el cual el proceso se completa menos el tiempo de arribo al sistema:
Debido a 2 el \(T_{arrival}=0\)
Hay que notar que el turnaround time es una métrica que mide performance.
Políticas Para Sistemas Mono-procesador¶
Se estudiarán las políticas de planificación para un sistema que posea un solo procesador o CPU con un solo núcleo de procesamiento.
First In, First Out (FIFO)¶
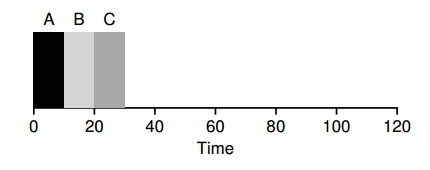
El algoritmo más básico para implementar como política de planificaciones es el First In First Out o Fist Come, First Served. Ventajas: 1. Es simple. 2. Por 1 es fácil de implementar. 3. Funciona bárbaro para las suposiciones iniciales.
Por ejemplo se tiene tres procesos A, B y C con \(T_{arrival}=0\). Si bien llegan todos al mismo tiempo llegaron con un insignificante retraso de forma tal que llegó A, B y C. Si se asume que todos tardan 10 segundos en ejecutarse… ¿cuánto es el \(T_{around}\)?
Esto puede apreciarse en la imagen :
Ahora relajemos la suposición 1 y no se asume que todas las tareas duran el mismo tiempo. Ahora A dura 100 segundos. ¿Cuánto es el \(T_{around}\)?
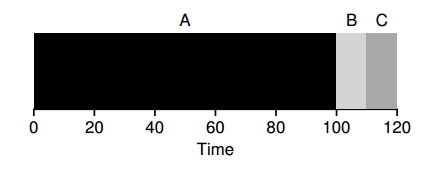
Segundos en promedio… un desastre esto se llama convoy effect.

Shortest Job First (SJF)¶
Para resolver el problema que se presenta en la política FIFO, se modifica la política para que se ejecute el proceso de duración mínima, una vez finalizado esto se ejecuta el proceso de duración mínima y así sucesivamente.
En el mismo caso de arriba, se mejora el turnaround time con el sencillo hecho de ejecutar B, C y A en ese orden:
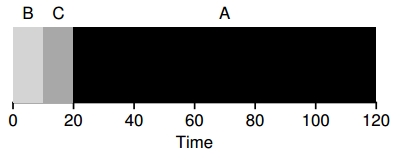
Utilizando SJF se obtuvo una significativa mejora… pero con las suposiciones iniciales que son muy poco realistas. Si se relaja la suposición 2, en la cual no todos los procesos llegan al mismo tiempo, por ejemplo llega el proceso A y a los 10 segundos llegan el proceso B y el proceso C. ¿Cómo seria el cálculo, ahora? _t_=10 seg
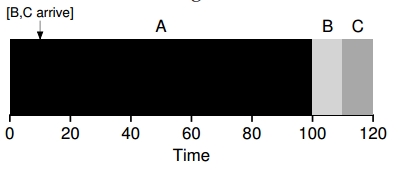
Shortest Time-to-Completion (STCF)¶
Para poder solucionar este problema se necesita relajar la suposición 3 (los procesos se tienen que terminar hasta el final). La idea es que el planificador o scheduler pueda adelantarse y determinar qué proceso debe ser ejecutado. Entonces cuando los procesos B y C llegan se puede desalojar (preempt [^1]) al proceso A y decidir que otro proceso se ejecute y luego retomar la ejecución del proceso A.
El caso anterior el de SFJ es una política non-preemptive
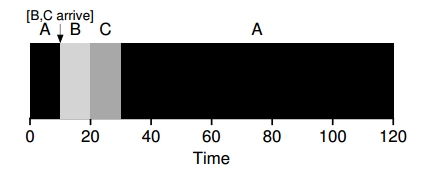
El cálculo para el turnaround time sería
Una nueva métrica: Tiempo de Respuesta¶
El tiempo de respuesta o response time surge con el advenimiento del time-sharing ya que los usuarios se sientan en una terminal de una computadora y pretenden una interacción con rapidez. Por eso nace el response time como métrica:
para entender la definición véase el caso anterior:
El \(T_{response}_\) del proceso A es 0.
El \(T_{response}_\) del proceso B es… 0… llega en 10 pero tarda 10 (10-10)
El \(T_{response}_\) del proceso C es… 10… llega en 10 pero termina en 20 (20-10)
En promedio el T_{response}_ es de 3.33 seg. Entonces ¿cómo escribir un planificador que tenga noción del tiempo de respuesta?
Round Robin (RR)¶
La idea del algoritmo es bastante simple, se ejecuta un proceso por un período determinado de tiempo (slice) y transcurrido el período se pasa a otro proceso, y así sucesivamente cambiando de proceso en la cola de ejecución [Round Robin Paper](/sisop_readings/ANALYSIS OF A TIME-SHARED PROCESSOR.pdf).
Los procesos A, B y C llegan a ejecutarse en el mismo instante y tardan 5 segundos, si se utiliza SJF:
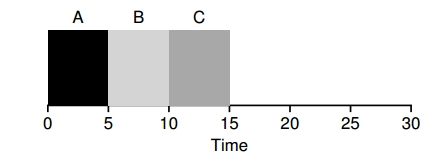
El tiempo de respuesta promedio sería 1 para RR con time slice de 1 seg:
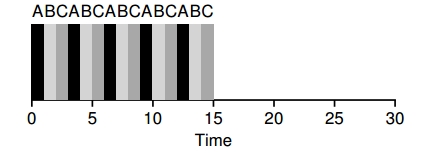
Lo importante de RR es la elección de un buen time slice, se dice que el time slice tiene que amortizar el cambio de contexto sin hacer que esto resulte en que el sistema no responda más.
Por ejemplo, si el tiempo de cambio de contexto está seteado en 1 ms y el time slice está seteado en 10 ms, el 10% del tiempo se estará utilizando para cambio de contexto.
Sin embargo, si el time slice se setea en 100 ms, solo el 1% del tiempo será dedicado al cambio de contexto. ¿Qué pasa si se trae a colación a la métrica del turnaround time ? Rpta:[^2]
Que pasa cuando hay Entrada y salida de datos… Capitulo 7 del Arpachi y Capitulo 7 del Dahlin
La Planificación en la vida real¶
¿Qué debería proporcionar un marco de trabajo básico que permita pensar en políticas de planificaciones ?
¿Cuáles deberían ser las suposiciones a tener en cuenta?
¿Cuáles son las métricas importantes?
Multi-Level Feedback Queue (MLFQ)¶
Esta técnica llamada Multi-Level Feedbak Queue de planificación fue descripta inicialmente en los años 60 en un sistema conocido como Compatible Time Sharinkg System CTSS. Este trabajo en conjunto con el realizado sobre MULTICS llevó a que su creador ganara el Turing Award.
Este planificador ha sido refinado con el paso del tiempo hasta llegar a las implementaciones que se encuentran hoy en un sistema moderno.
MLQF intenta atacar principalmente 2 problemas:¶
Intenta optimizar el turnaround time, que se realiza mediante la ejecución de la tarea mas corta primero, desafortunadamente el sistema operativo nunca sabe a priori cuanto va a tardar en correr una tarea.
MLFQ intenta que el planificador haga sentir al sistema con un tiempo de respuesta interactivo para los usuarios por ende minimizar el *response time*; desafortunadamente los algoritmos como round-robin reducen el *response time* pero tienen un terrible *turnaround time*.
Entonces:
¿Cómo se hace para que un planificador pueda lograr estos dos objetivos si generalmente no se sabe nada sobre el proceso a priori?.
¿Cómo se planifica sin tener un conocimiento acabado?
¿Cómo se construye un planificador que minimice el tiempo de respuesta para las tareas interactivas y también minimice el *timearound* time sin un conocimiento a priori de cuanto dura la tarea?
MLQF: Las reglas básicas¶
MLFQ tiene un conjunto de distintas colas, cada una de estas colas tiene asignado un nivel de prioridad.
En un determinado tiempo, una tarea que está lista para ser corrida está en una única cola. MLFQ usa las prioridades para decidir cual tarea debería correr en un determinado tiempo t0: la tarea con mayor prioridad o la tarea en la cola mas alta sera elegida para ser corrida.
Dado el caso que existan mas de una tarea con la misma prioridad entonces se utilizara el algoritmo de Round Robin para planificar estas tareas entre ellas.
Las 2 reglas básicas de MLFQ:
REGLA 1: si la prioridad (A) es mayor que la prioridad de (B), (A) se ejecuta y (B) no.
REGLA 2: si la prioridad de (A) es igual a la prioridad de (B), (A) y (B)se ejecutan en Round-Robin.
La clave para la planificación MLFQ subyace entonces en cómo el planificador setea las prioridades. En vez de dar una prioridad fija a cada tarea, MLFQ varia la prioridad de la tarea basándose en su comportamiento observado.
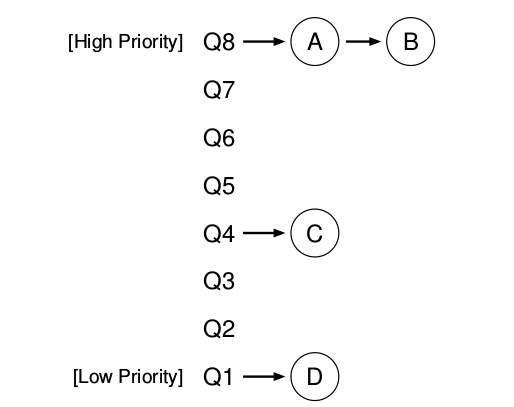
Por ejemplo, si una determinada tarea repetidamente no utiliza la CPU mientras espera que un dato sea ingresado por el teclado, MLFQ va a mantener su prioridad alta, así es como un proceso interactivo debería comportarse.
Si por lo contrario, una tarea usa intensivamente por largos periodos de tiempo la CPU, MLFQ reducirá su prioridad. De esta forma MLFQ va a aprender mientras los procesos se ejecutan y entonces va a usar la historia de esa tarea para predecir su futuro comportamiento
(Figura 181 ARPACI)
Obviamente que una fotografía sobre MLFQ no va a dar una idea de como este trabaja lo que se necesita es entender como la prioridad de una tarea varia a través del tiempo.
Primer intento: ¿Cómo cambiar la prioridad ?¶
Se debe decidir como MLFQ va a cambiarle el nivel de prioridad a una tarea durante toda la vida de la misma (por ende en que cola esta va a residir). Para hacer esto hay que tener en cuenta nuestra carga de trabajo (workload): una mezcla de tareas interactivas que tienen un corto tiempo de ejecución y que pueden renunciar a la utilización de la CPU y algunas tareas de larga ejecución basadas en la CPU que necesitan tiempo de CPU , pero poco tiempo de respuesta. A continuación e muestra un primer intento de algoritmo de ajuste de prioridades:
REGLA 3: Cuando una tarea entra en el sistema se pone con la mas alta prioridad
REGLA 4a: Si una tarea usa un time slice mientras se esta ejecutando su prioridad se reduce de una unidad (baja la cola una unidad menor)
REGLA 4b: Si una tarea renuncia al uso de la CPU antes de un time slice completo se queda en el mismo nivel de prioridad.
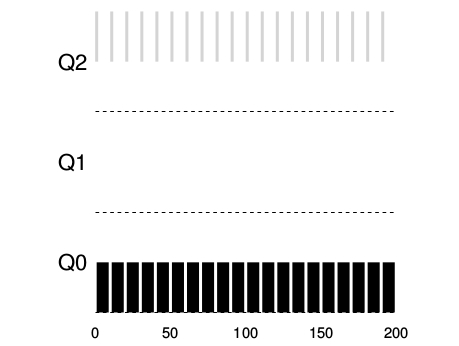
Ejemplo 1: Una única tarea con ejecución larga.¶
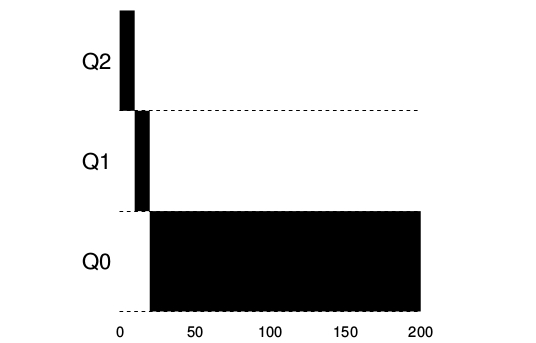
Ejemplo 2: Llega una tarea corta.¶
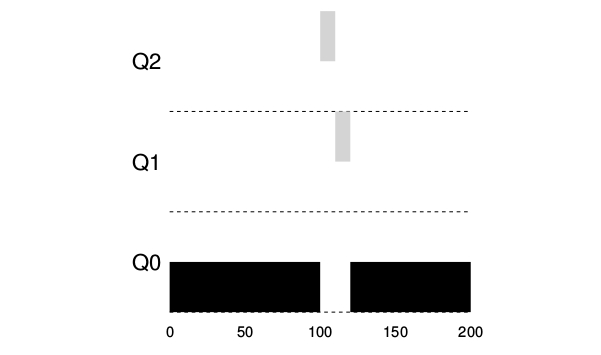
Existen 2 tareas, una de larga ejecución de CPU, A y B con una ejecución corta e interactiva. B tarda 20 milisegundos en ejecutarse. D e este ejemplo se puede ver una de las metas del algoritmo dado que no sabe si la tarea va a ser de corta o larga duración de ejecución, inicialmente asume que va a ser corta, entonces le da la mayor prioridad. Si realmente es una tarea corta se va a ejecutar rápidamente y va a terminar, si no lo es se moverá lentamente hacia abajo en las colas de prioridad haciéndose que se parezca mas a un proceso BATCH .
Ejemplo 3: Que pasa con la entrada y salida.¶
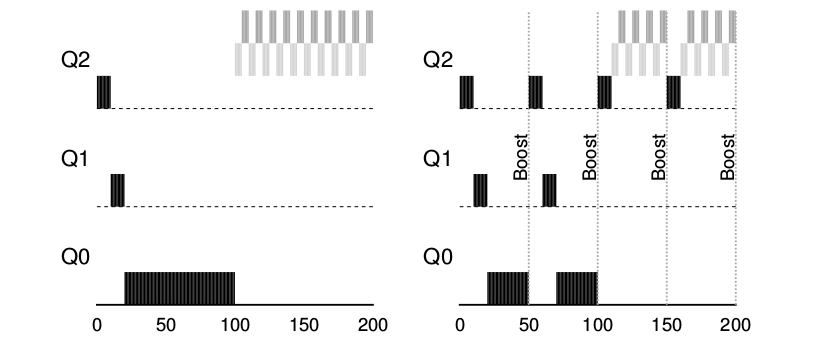
Como se considera en la regla 4 si la tarea renuncia al uso del procesador antes de un time slice se mantiene en el mismo nivel de prioridad. EL objetivo de esta regla es simple: si una tarea es interactiva por ejemplo entrada de datos por teclado o movimiento del mouse esta no va a requerir uso de CPU antes de que su time slice se complete en ese caso no sera penalizada y mantendrá su mismo nivel de prioridad.
PROBLEMA Con este Approach de MLFQ¶
Starvation : Si hay demasiadas tareas interactivas en el sistema se van a combinar para consumir todo el tiempo del CPU y las tareas de larga duración nunca se van a ejecutar.
Un usuario inteligente podría reescribir sus programas para obtener mas tiempo de CPU por ejemplo: Antes de que termine el time slice se realiza una operación de entrada y salida entonces se va a relegar el uso de CPU haciendo esto se va a mantener la tarea en la misma cola de prioridad. Entonces la tarea puede monopolizar toda el tiempo de CPU.
Segundo Approach¶
¿ Cómo mejorar la prioridad?
Para cambiar el problema del starvation y permitir que las tareas con larga utilización de CPU puedan progresar lo que se hace es aplicar una idea simple, se mejora la prioridad de todas las tareas en el sistema. Se agrega una nueva regla:
Regla 5: Después de cierto periodo de tiempo S, se mueven las tareas a la cola con mas prioridad.
Haciendo esto se matan 2 pájaros de 1 tiro:
Se garantiza que los procesos no se van a starve: Al ubicarse en la cola tope con las otras tareas de alta prioridad estos se van a ejecutar utilizando round-robin y por ende en algún momento recibirá atención.
si un proceso que consume CPU se transforma en interactivo el planificador lo tratara como tal una vez que haya recibido el boost de prioridad.
Obviamente el agregado del periodo de tiempo S va a desembocar en la pregunta obvia: Cuanto debería ser el valor del tiempo S. Algunos investigadores suelen llamar a este tipo de valores dentro de un sistema VOO-DOO CONSTANTs porque parece que requieren cierta magia negra para ser determinados correctamente.
Este es el caso de S, si el valor es demasiado alto,los procesos que requieren mucha ejecución van a caer en starvation; si se setea a *S* con valores muy pequeños las tareas interactivas no van a poder compartir adecuadamente la CPU.
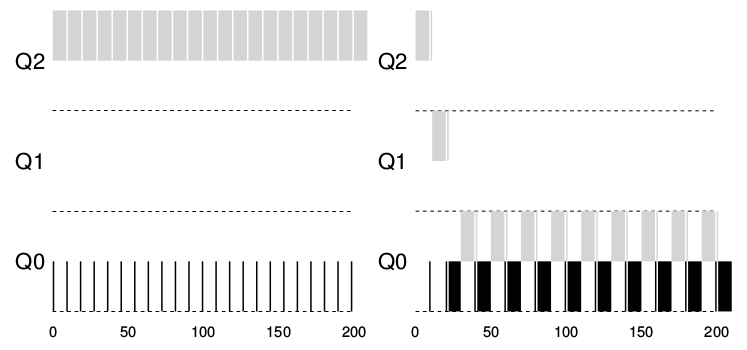
Se debe solucionar otro problema: Como prevenir que ventajeen (gaming) al planificador.
La solución es llevar una mejor contabilidad del tiempo de uso de la CPU en todos los niveles del MLFQ.
En lugar de que el planificador se olvide de cuanto time slice un determinado proceso utiliza en un determinado nivel el planificador debe seguir la pista desde que un proceso ha sido asignado a una cola hasta que es trasladado a una cola de distinta prioridad. Ya sea si usa su time slice de una o en pequeños trocitos, esto no importa por ende se reescriben las reglas 4a y 4b en una única regla:
Regla 4: Una vez que una tarea usa su asignación de tiempo en un nivel dado (independientemente de cuantas veces haya renunciado al uso de la CPU) su prioridad se reduce: ( Por ejemplo baja un nivel en la cola de prioridad)
Resumen:¶
Se vio la técnica de planificación conocida como multi-level feed back qeque (MLFQ). Se puede ver porque es llamado así, tiene un conjunto de colas de multiniveles y utiliza feed back para determinar la prioridad de una tarea dada. La historia es su guía: Poner atención como las tareas se comportas a través del tiempo y tratarlas de acuerdo a ello. Las reglas que se utilizan son:
REGLA 1: si la prioridad (A) es mayor que la prioridad de (B), (A) se ejecuta y (B) no.
REGLA 2: si la prioridad de (A) es igual a la prioridad de (B), (A) y (B)se ejecutan en Round-Robin.
REGLA 3: Cuando una tarea entra en el sistema se pone con la mas alta prioridad
Regla 4: Una vez que una tarea usa su asignación de tiempo en un nivel dado (independientemente de cuantas veces haya renunciado al uso de la CPU) su prioridad se reduce: ( Por ejemplo baja un nivel en la cola de prioridad).
Regla 5: Después de cierto periodo de tiempo S, se mueven las tareas a la cola con mas prioridad.
Planificación Avanzada: Planificación multiprocesador¶
En los últimos años los sistemas multi-procesadores han ido creciendo en los lugares comunes de la informática como por ejemplo en las computadores desktop, laptops y dispositivos móviles. El advenimiento de los procesadores multi-núcleo, en los cuales múltiples núcleos de CPU están empaquetados en un único chip, en nuestros días esa arquitectura esta en plena proliferación. Este tipo de arquitectura de procesadores se volvió popular debido a que es complicado construir CPU cada vez mas rápidas y que a su vez las mismas no se fundan por el calor producido por la potencia que consumen.
Por supuesto que tener muchos procesadores en un único chip conlleva un conjunto de dificultades:
Una aplicación típica por ejemplo un programa escrito en C usa únicamente una CPU:
por lo cual agregar mas CPU no implica que la aplicación corra de forma mas rápida. El remedio a este problema es la necesidad de escribir aplicaciones que corran en paralelo, por ejemplo usando threads.
Las aplicaciones multithreads pueden diseminar el trabajo a lo largo de múltiples CPUs y por ende correr mas rápido cuantas mas CPU hayan.
Mas allá de las aplicaciones sale a la luz una nueva problemática que es la planificación en multiprocesadores.
La arquitectura multiprocesador¶
Para poder entender cuales son los problemas que atañan a la planificación multiprocesador en primer lugar hay que entender cual es la diferencia fundamental entre hardware monoprocesador y hardware multi-procesador.
La diferencia se centra básicamente alrededor de un tipo de hardware llamado cache,y de que forma exactamente los datos en la cache son compartidos a través de los multiprocesadores.
En un sistema con único CPU hay una jerarquía de el hardware de cache que generalmente ayuda al procesador a correr los programas mas rápidamente. Las cache son pequeñas y rápidas memorias que (generalmente) mantienen copias de datos que son comúnmente utilizados que se encuentran en la memoria principal del sistema.
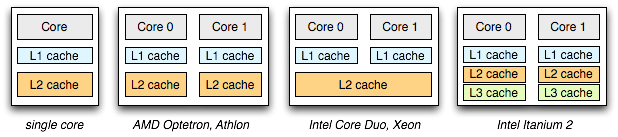
La memoria principal, por el contrario mantienen todos los datos del sistema pero el acceso a los mismos es lento. A través de mantener los datos que son frecuentemente utilizados en la cache, el sistema puede hacer que una memoria larga y lenta parezca una memoria rápida.
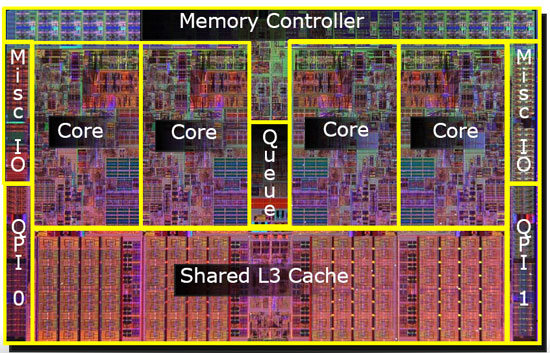
Como ejemplo, se puede considerar un programa que le diga implícitamente a una instrucción e ir a buscar un determinado valor de la memoria, si se tiene un sistema con una única CPU, con un pequeño cache de 64 Kb y una memoria principal muy larga:
La primera vez que se realice la carga, los datos estarán reduciendo en la memoria principal, y esto por lo tanto llevara un largo tiempo de fetch ( probablemente unos días nanosegundos o incluso unos cientos de nano segundos).
EL procesador, anticipando que esos datos podrían ser reutilizados, pone una copia de los datos cargados en el cache de la CPU.
Si el programa requiere el mismo conjunto de datos otra vez, la CPU en primer lugar los va a ir a buscar al cache; si los encuentra ahí los datos son llevados a la CPU mucho mas rápidamente( probablemente en unos pocos nanosegundos), entonces el programa parecerá ejecutarse mas rápidamente.
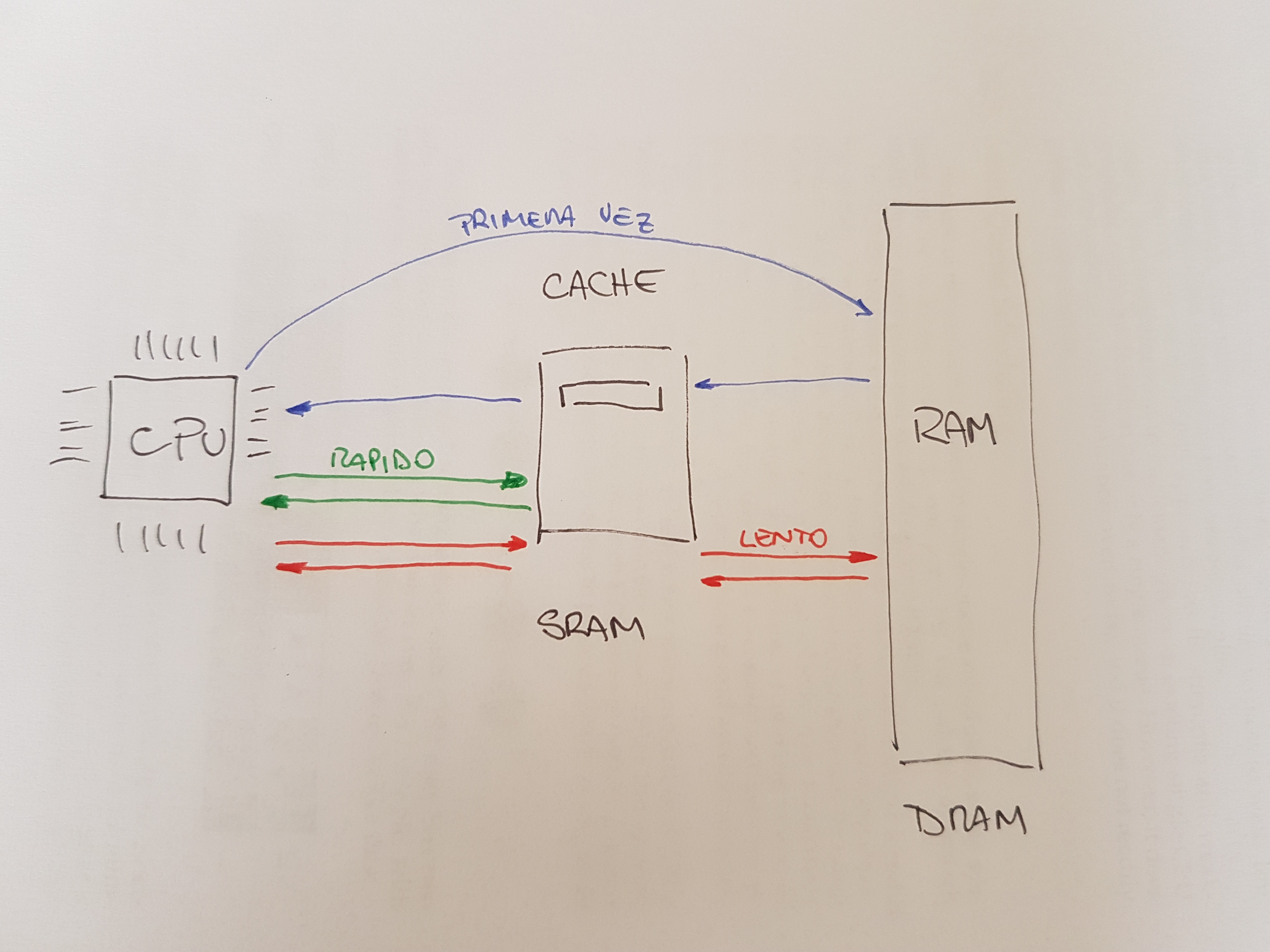
Entonces las cache se basan en la noción de localidad, de la cual hay dos tipos: localidad temporal y localidad espacial.
La idea detrás de la localidad temporal es que cuando cierta cantidad de datos son accedidos, es muy probable que sean accedidos otra vez ne un futuro cercano; imaginar por ejemplo variables o instrucciones que se ejecutan una y otra vez en un ciclo.
La idea detrás de la localidad espacial se basa en que un programa que accede a una dirección X es muy probable que necesite volver a acceder cerca de X. Acá podría pensarse en un programa sobre un arreglo. Teniendo en cuenta que este tipo de localidad existe en la mayoría de los programas los sistemas de hardware pueden hacer buen uso de las cache.
El código fuente escrito por los humanos tiene ambos tipos de localidades:
for(i = 0; i < 20; i++)
for(j = 0; j < 10; j++)
a[i] = a[i]*j;
La localidad temporal se refiere a cuando la misma posición de memoria es referenciada por muchas veces en un lapso de tiempo muy corto. Por ejemplo, en el código de arriba a[i] es referenciada frecuentemente en el ámbito del ciclo en a[i] = a[i] * 2 o a[i] = a[i] * 3. Dentro del mismo ámbito, se puede decir que i y j tiene localidad temporal.
La localidad espacial tiene que ver con la referencia de variables que están en posiciones contiguas de memoria a[0] y a[1] por ejemplo.
¿Que sucede cuando múltiples procesadores en un único sistema tiene que compartir una única memoria principal?
Como se verá el cacheo con múltiples CPU es mucho mas complicado. Imaginarse, por ejemplo, que un programa que se esta ejecutando en la CPU1 lee un dato cuyo valor es D en la dirección de memoria A:
Debido a su este dato no esta cacheado en la CPU1, el sistema lo trae de la memoria principal y toma este valor D.
El programa entonces modifica el valor en la dirección A, esto se realiza actualizando su valor D1; dado que escribir los datos directamente en la memoria principal es muy lento, el sistema habitualmente lo deja para mas tarde.
Entonces se asume que el OS decide parar de ejecutar un programa y mover este programa a la CPU 2.
EL programa entonces vuelve a ejecutarse en la CPU 2 y relee el valor en la dirección A;
porque no existe tal valor en la cache de la CPU2, entonces el sistema trae el valor de memoria desde la memoria principal y obtiene el viejo valor D en vez del correcto valor D prima. OOPS!.
Este problema es generalmente llamado coherencia del cache, existe muchísima bibliográfica que describe las diferentes sutilezas en solucionar este tipo de problemas que en este curso no se verán.
La solución básica que el hardware provee es mediante la monitorización de los accesos a memoria, el hardware se asegura básicamente que las cosas pasen bien y que la vista de una única memoria compartida sea preservada. Una forma de hacer esto en un sistema basa en Bus, usando una vieja técnica llamada Bus Snooping:
Cada cache pone atención en las actualizaciones de memoria mediante la observación del bus que esta conectado a ellos y a la memoria principal. Cuando una CPU entonces ve que se actualizo un dato que esta mantenido en su propio cache esta se va a dar cuenta de tal cambio y va a invalidar su copia (por ejemplo sacándola de su propio cache) o lo actualiza (por ejemplo poniendo el nuevo valor en su cache)
Existen otros métodos mas complicados de hacer esto.
Dado que la cache hace todo el trabajo para mantener la coherencia del sistema, tienen que los programas preocuparse de algo cuando acceden a memoria compartida? La respuesta es desafortunadamente si y se vera en el capitulo de concurrencia.
Afinidad de Cache¶
El último tema a tener en cuenta cuando se arma un planificador con multiprocesadores con cache, es conocida como la afinidad de cache o cache affinity.
El concepto es básico:
Cuando un proceso corre sobre una CPU en particular va construyendo un cachito del estado de si mismo en las cache de esa CPU
Entonces la próxima vez que el proceso se ejecute seria bastante interesante que se ejecutara en la misma CPU, ya que se va a ejecutar mas rápido si parte de su estado esta en esa CPU.
Si, en cambio se ejecuta el proceso en una CPU diferente cada vez, el rendimiento del proceso va a ser peor, ya que tendrá que volver a cargar su estado o parte del mismo cada vez que se ejecute.
Por ende un planificador multiprocesador debería considerar la afinidad de cache cuando toma sus decisiones de planificación, tal vez prefiriendo mantener a un proceso en un determinado CPU si es posible.
Planificación de cola única¶
La forma mas fácil para tener un planificador para un sistema multiprocesador es la de reutilizar el marco de trabajo básico para un planificador de monoprocesador.
Entonces se ponen todos los trabajos que tienen que ser planificados en una única cola, que se llamara SINGLE QUEUE MULTIPROCESSOR SCHEDULING o SQMS.
Esta forma de plantear la planificación tiene la ventaja de la simplicidad ya que no requiere mucho trabajo tomar la política existente que agarra la mejor tarea y la pone a ejecutar y adaptarla para que trabaje con mas de una CPU. sin embargo, SQMS tiene sus limitaciones:
No es escalable
Para asegurarse que la planificación trabaje correctamente en una arquitectura de múltiple CPU los desarrolladores tienen que insertar algún tipo de bloqueo en su código fuente. Es decir el bloqueo tiene que asegurar que cuando SQMS accede a una única cola (como para encontrar la próxima tarea a ejecutar), un resultado correcto se ha obtenido. EL bloqueo desafortunadamente va a reducir en mucho la performance particularmente a medida que el numero de CPU del sistema empiece a crecer. Téngase en cuenta que con un único bloqueo, el sistema pierde mas tiempo sobrecargándose en el bloqueo y menos tiempo en lo que debería estar haciendo.
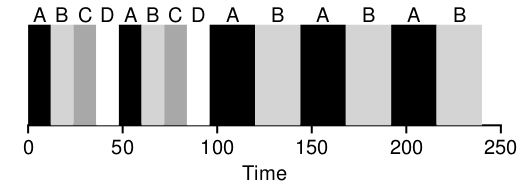
Otro gran problema de SQMS es la afinidad del cache. Por ejemplo, si se asume que se tienen 5 tareas ( A, B, C, D )y 4 procesadores entonces la cola de planificación se vería de esta forma:

A lo largo del tiempo, asumiendo que cada trabajo se ejecuta en un determina time slice otro trabajo es elegido para ser ejecutado y entonces un posible esquema de planificación a través de la CPU podría ser:
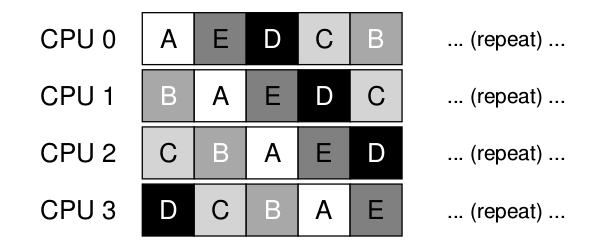
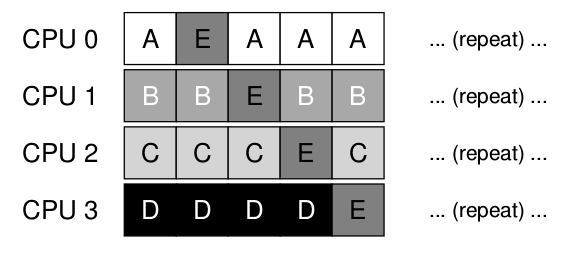
Teniendo en cuenta que cada CPU va a agarrar el próximo trabajo a ser ejecutado de la cola global compartida, cada tarea va a terminar saltando de CPU en CPU, haciendo exactamente lo opuesto de lo que recomienda la afinidad de cache mas bien que los procesos continúen ejecutándose en la misma CPU si es posible. En algunos casos se podría proveer a ciertas tareas con cierta afinidad y a otras dejarlas cambiando de CPU para balancear la carga por ejemplo mirar:
Multi-Queue Planificacion¶
Debido a los problemas que tiene single queue scheduler varia gente opto por crear un planificador multi queue que se llama MULTI-QUEUE MULTIPROCESSOR SHCHEDULING en MQMS.
El esquema básico de la planificación consiste en múltiples colas. Cada cola va a seguir una determinada disciplina de planificación, por ejemplo, round robin, cuando una tarea entra en el sistema ésta se coloca exactamente en una única cola de planificación, de acuerdo con alguna heuristica. Esto implica que es esencialmente planificada en forma independiente.
Por ejemplo, Si se asume que se está trabajando con un sistema de dos procesadores ( CPU0 y CPU1) y una determinada cantidad de tareas ingresan al sistema ( A, B, C y D , por ejemplo). Dado que cada CPU tiene exactamente 2 colas, el planificador podría decidir distribuir las tareas de la siguiente forma:

Dependiendo de la política de planificación por ejemplo Round Robin, la planificación a lo largo del tiempo podría verse así :

MQMS tiene la ventaja sobre SQMS debido a que es enteramente escalable. A medida que las CPU van creciendo también lo hacen las colas, lo que conlleva a que los lock y las cache no sean ya un problema.
MQMS intrínsecamente prvee afinidad de cache, es decir las tareas intentan mantenerse en la CPU en la que fueron planificadas.
El único problema de MQSM es el load imbalance. El load imbalance se dá cuando una CPU queda ociosa frente a las demás que están sobrecargadas. por ejemplo, si se asume que se esta en el mismo escenario que en el ejemplo anterior 2 CPUs 4 tareas, pero una de las tareas, por ejemplo la C termina :
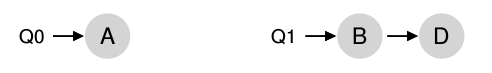
la política de Round Robin resultaría :

Como puede verse en el diagrama , A tendría el doble de uso de CPU que B y D.

Un caso que sería aún pero es que también A termine, lo que conllevaría a que la CPU0 estuviera ociosa

La pregunta que se plantea es ¿Cómo se resuelve el problema del load imbalance?
La respuesta más obvia es aquella de mover las tareas de un lado a otro, esta técnica se conoce como migración o migration. Mediante la migración de una tarea a otra cpu se puede conseguir un verdadero balance de carga.
Otra vez se considera la situación donde una CPU esta ociosa y la otra tiene algunas tareas:
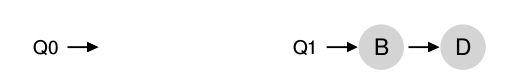
En este caso la migración deseada es fácil de comprender: se debería mover la tarea B o D a la CPU0. con un resultado win-win.
Una situación un poco más complicada sería en el caso en que A fue dejada sola en la CPU0. Para esta situación la migración de una sola tarea no serviría de nada. La idea es que las tres tareas migren por las dos CPUs quedado un esquema como el siguiente:
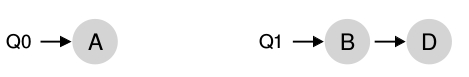

La Vida Real¶
El planificador de tareas de Linux desde su primer versión en 1991 pasando por todas hasta el kernel versión 2.4 fue sencillo y casi pedestre en lo que respecta a su diseño [LOV], cap. 4. Durante la versión 2.5 del kernel el scheduler sufrió una serie de revisiones. Un nuevo planificador vio la luz del día llamado ** O(1) scheduler ** debido a su comportamiento algoritmico. Este introdujo un algoritmo que calculaba en tiempo constante:
el time-slice
las colas de ejecución por proceso
Si bien el planificador O(1) estaba muy bueno para equipos servidores no funcionaba tan bien para procesos con interacción con usuarios procesos interactivos*. En las revisiones del kernel 2.6 se introdujeron nuevas mejoras en lo que respecta a los procesos interactivos del planificador O(1), Con Kolivas, introdujo el concepto de Rotating Starircase Deadline scheduler, que introduce el concepto de fair scheduling.
Una característica importante de CFS es que el mismo no otorga un determinado time slice a un proceso. Sino que este le otorga una proporción del procesador. Esta porcion del tiempo de procesador que el proceso recibe es función de la carga del sistema.
Linux: Completelly Fair Scheduler (CFS)¶
El planificador de linux llamado Completelly Fair implementa le que se denomina fair-share scheduling de una forma altamente eficiente y de forma escalable.
Para lograr la meta de ser eficiente, CFS intenta gastar muy poco tiempo tomando decisiones de planificación, de dos formas :
Por su diseño
Debido al uso inteligente de estructuras de datos para esa tarea
Modo de Operación Básico:¶
Mientras que los planificadores tradicionales se basan alrededor del concepto de un tima-slice fijo, CFS opera de forma un poco diferente. Su objetivo es sencillo: dividir de forma justa la CPU entre todos los procesos que están compitiendo por ella. Esto lo hace mediante una simple técnica para contar llamada virtual runtime (Vruntime). El vruntime no es mas que que el runtime (es decir el tiempo que se esta ejecutando el proceso) normalizado por el número de processos runnable (se mide en nanosegundos)
A medida que un proceso se ejecuta este acumula vruntime. En el caso más básico cada vruntaime de un proceso se incrementa con la misma tasa, en proporción al tiempo (real) físico. Cuando una decisión de planificación ocurre, CFS seleccionará el proceso con menos vruntime para que sea el próximo en ser ejecutado.
Esto lleva a una pregunta:¿Como sabe el planificador cuando parar de ejecutar el proceso que esta corriendo y correr otro proceso? El punto clave aquí es que hay un punto de tensión entre performance y equitatividad:
si el CFS switche de proceso en tiempos muy pequeños estará garantizando que todos lo proceso se ejecuten a costa de perdida de performance, demasiados context switches
si CFS switchea pocas veces, la performance del scheduler es buena pero el costo está puesto del lado de la equitatividad (fairness).
La forma en que CFS maneja esta tensión es mediante varios parámetros de control.
sched_latency, este valor determina por cuanto tiempo un proceso tiene que ejecutarse antes de considerar su switcheo. ( es como un time-slice pero dinámico). Un valor típico de este parámetro es de 48 ms, CFS divide este valor por el numero de procesos ($n$) ejecutándose en la CPU para determinar el time-slice de un proceso, y entonces se asegura que por ese periodo de tiempo , CFS va a ser Completamente justo.
Por ejemplo, si $n=4$ procesos ejecutándose, CFS divide el valor de sche_latency por $n$ asignándole a cada proceso 12 ms. CFS planifica el primer job y lo ejecuta hasta que ha utilizado sus 12 ms de (virtual) runtime, y luego chequea si hay algún otro proceso con menos vruntime, si lo hay switchea a este.
Bueno, pero si hay muchos procesos ejecutándose esto no llevaría a muchos context swtiches y por ende pequeños time slices? Sí.
Para lidiar con este problema se introduce otro parámetro llamado min_granularity, que normalmente se setea con el valor de 6 ms. Entonces CFS nunca sedearía el time-slice de un proceso por debajo de ese número, por ende con esto se asegura que no haya overhead por context switch.
CFS utiliza una interrupción periódica de tiempo, lo que significa que sólo puede tomar decisiones en periodos de tiempos fijos(1ms)
Weighting (Niceness)¶
CFS tiene control sobre las prioridades de los procesos, de forma tal que los usuario y administradores puedan asignar mas CPU a un determinado proceso. Esto se hace con un mecanismo cálcico de unix llamado nivel de proceso nice , este valor va de -20 a +19, con un valor por defecto de 0. Con una característica un poco extraña: los valores positivos de nice implican una prioridad más baja, y los valores negativos de nice implican una prioridad más alta.
CFS mapea el nice value con un peso como se muestra :
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
Estos pesos permite calcular efectivamente el time slice para cada proceso (como se hizo antes) peeero teniendo en cuenta las distintas prioridades para cada proceso:
Por ejemplo, supongamos que se tienen dos procesos A y B. A es muy importante por ende le asignamos un alta prioridad asignándole un valor de nice de -5; por otro lado B nos cae antipático y se le asigna la prioridad por defecto (nice =0). Viendo la tabla el \(weight_{A}\) es de 3121 y el \(weight_{B}\) es 1024. ¿Cuanto es el time_slice de cada uno?
Con esto se debe generalizar el calculo de vruntime:
Este se calcula tomando el tiempo de ejecución real que el \(proceso_{i}\) ha acumulado (\(runtime_{i}\)) y lo escala de manera inversa según el peso del proceso.
Un aspecto inteligente de la construcción de la tabla de pesos anterior es que la tabla conserva las proporciones de ratio de la CPU cuando la diferencia en valores de nice es constante. Por ejemplo, si el proceso A en su lugar tenía un buen valor de 5 (no -5), y el proceso B tenía un buen valor de 10 (no 0), CFS los programaría exactamente de la misma manera que antes. Probarlo el cálculo usted mismo para ver por qué.
Utiliza Arboles Rojo-Negro¶
Uno de los focos de eficiencia del CFS está en la implementación de las políticas anteriores. Pero también en una buena selección del tipo de dato cuando el planificador debe encontrar el próximo job a ser ejecutado.
Las listas no escalan bien \(O(n)\)
Los árboles sí, en este caso los árboles Rojo-Negro \(O(log n )\)
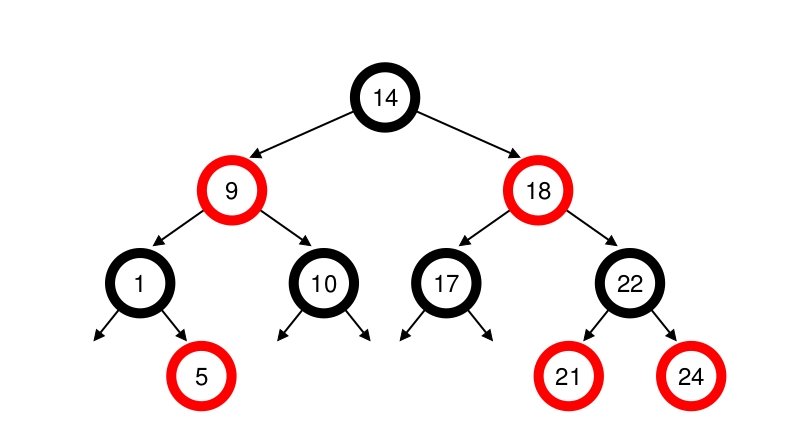
Para tener una idea cerrada de donde aparece el árbol rojo y negro dentro del kernel de linux a partir de la versión del kernel 2.6.0, ver la siguiente imagen:
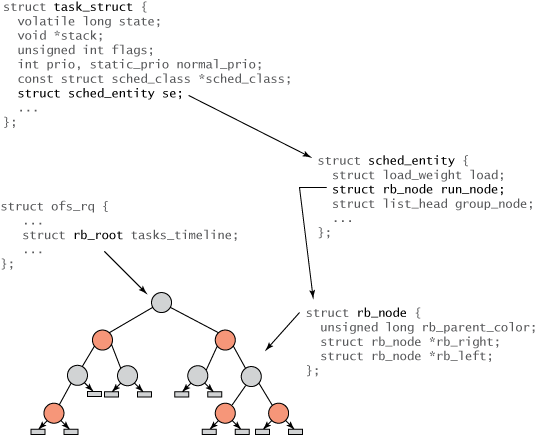
El Algoritmo:¶
Cuando el scheduler es invocado para correr un nuevo proceso, la forma en que el scheduler actua es la siguiente:
El nodo más a la izquierda del árbol de planificación es es elegido (ya que tiene el tiempo de ejecución más bajo), y es enviado a ejecutarse.
Si el proceso simplemente completa su ejecución, este es eliminado del sistema y del árbol de planificación.
Si el proceso alcanza su máximo tiempo de ejecución o de otra forma se para la ejecución del mismo voluntariamente o vía una interrupción) este es reinsertado en el árbol de planificación basado en su nuevo tiempo de ejecución (vruntime).
El nuevo nodo que se encuentre más a la izquierda del árbol será ahora el seleccionado, repitiéndose así la iteración.
unix xv6¶
El enfoque que utilizan los sistemas operativos para crear la ilusión de que cada proceso tiene su propio procesador virtual es mediante la multiplexación de los procesos sobre el hardware disponible.
Xv6 multiplexa cambiando en cada procesador un proceso por otro en dos ocasiones:
Los mecanismos de xv6 sleep y wakeup cambian cuando un proceso espera que se complete una operación de I/O, cuando espera por la finalización de un proceso hijo (wait) o cuando el proceso espera en la system call sleep().
Xv6 periódicamente fuerza un cambio cuando un proceso de usuario se está ejecutando.
Esto crea la ilusión de que cada proceso tiene su propia CPU, entre otras cosas. Este cambio entre procesos se traduce en un cambio entre modo usuario - modo kernel - modo usuario .
existe una función llamada swtch, que cuando es hora que un proceso salga del CPU este llama a la función swtch, que guardará su contexto y cargará el contexto del scheduler.
Cada contexto se guarda en un struct context , por ende la función swtch ( struct contex * old, struct context * new)
// Per−CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// − choose a process to run
// − swtch to start running that process
// − eventually that process transfers control
// via swtch back to the scheduler.
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c−>proc = 0;
for(;;){
// Enable interrupts on this processor.
sti();
// Loop over process table looking for process to run.
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p−>state != RUNNABLE)
continue;
// Switch to chosen process. It is the process’s job
// to release ptable.lock and then reacquire it
// before jumping back to us.
c−>proc = p;
switchuvm(p);
p−>state = RUNNING;
swtch(&(c−>scheduler), p−>context);
switchkvm();
// Process is done running for now.
// It should have changed its p−>state before coming back.
c−>proc = 0;
}
release(&ptable.lock);
}
}