El Proceso¶
De Programa a Proceso¶
Una vez que se edita un programa en cualquier lenguaje de programación se debe compilar para poder obtener un programa ejecutable.
#include <stdio.h>
int main() {
printf("hello, world\n");
}
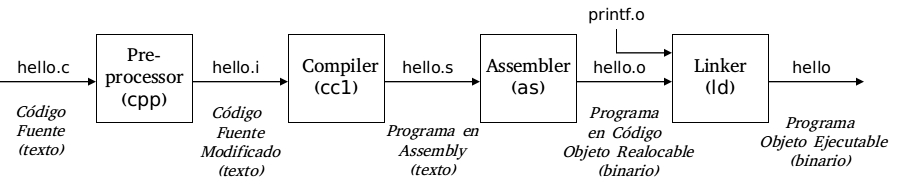
Compilar que en la actualidad suele considerarse como una actividad atómica, está separada en varias etapas en las cuales se utilizan distintas herramientas y se obtienen distintos archivos en distintos formatos hasta alcanzar el formato ejecutable. Sin el compilador el programa se limita a ser:

Las fase de compilación son 4 etapas, que utilizan 4 herramientas para llevar a cabo cada una de estas etapas. Estas herramientas son: * el preprocesador. * el compilador * el ensamblador * el link editor o linker.
Estas en conjunto son conocidas como un sistema de compilación.
La Compilación¶
La fase de procesamiento. El preprocesador (cpp) modifica el código de fuente original de un programa escrito en C de acuerdo a las directivas que comienzan con un caracter(#). El resultado de este proceso es otro programa en C con la extinción .i
La fase de compilacion. El compilador (cc) traduce el programa .i a un archivo de texto .s que contiene un programa en lenguaje assembly.
La fase de ensablaje. A continuación el ensamblador (as) traduce el archivo .s en instrucciones de lenguaje de máquina empaquetándolas en un formato conocido como programa objeto realocable. Este es almacenado en un archivo con extensión .o
La fase de link edicion. Generalmente los programas escritos en lenguaje C hacen uso de funciones que forman parte de la biblioteca estandar de C que es provista por cualquier compilador de ese lenguaje. Por ejemplo la función printf(), la misma se encuentra en un archivo objeto pre compilado que tiene que ser mezclado con el programa que se esta compilando, para ello el linker realiza esta tarea teniendo como resultado un archivo objeto ejecutable.
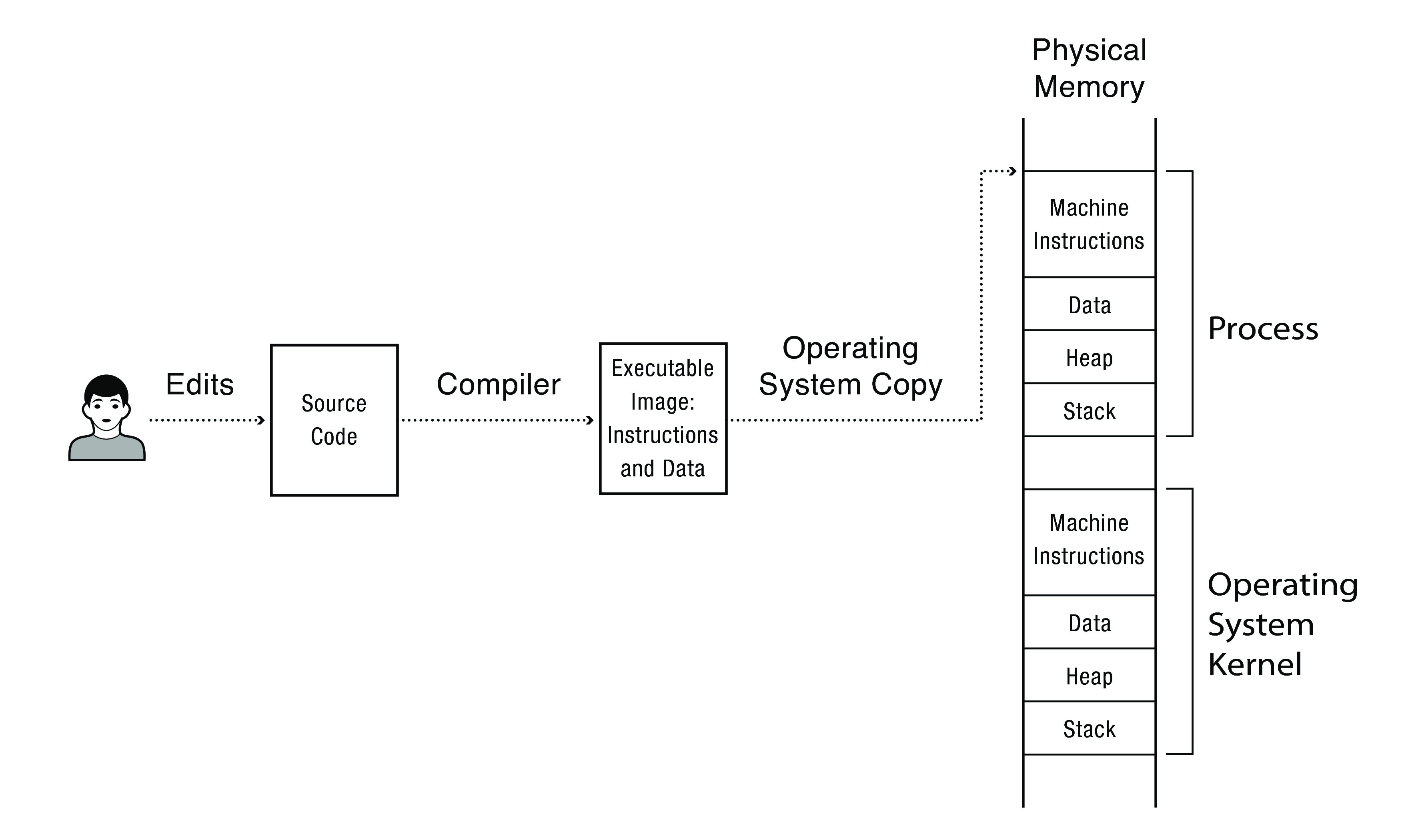
Programador edita código fuente
El compilador compila el source code en una secuencia de instrucciones de máquina y datos llamada.
El compilador genera esa secuencia y posteriormente se guarda en disco: programa ejecutable.
Un Programa en Unix¶
Un programa es un archivo que posee toda la información de como construir un proceso en memoria [KER](cap. 6). Un programa contiene:
Formato de Identificación Binaria: Cada archivo ejecutable posee META información describiendo el formato ejecutable. Esto permite al kernel interpretar la información contenida en el mismo archivo.
Recordar que por algo la salida del compilador C es por defecto a.out que viene de “assembler output”. Posteriormente, dos formatos han sido utilizados en la familia de sistemas operativos unix:
COFF (Common Object File Format”) utilizado en la mayoría de las versiones de System V.
ELF (Executable and Linking Format) utilizado en la actualidad.
Instrucciones de Lenguaje de Máquina: Almacena el código del algoritmo del programa.
Dirección del Punto de Entrada del Programa: Identifica la dirección de la instrucción con la cual la ejecución del programa debe iniciar.
Datos: El programa contiene valores de los datos con los cuales se deben inicializar variables, valores de contantes y de literales utilizadas en el programa.
Simbolos y Tablas de Realocación: Describe la ubicación y los nombres de las funciones y variables de todo el programa, así como otra información que es utilizada por ejemplo para debugg.
Bibliotecas Compartidas: describe los nombres de las bibliotecas compartidas que son utilizadas por el programa en tiempo de ejecución así como también la ruta del linker dinámico que debe ser usado para cargar dicha biblioteca.
Otra información: El programa contiene además otra información necesaria para terminar de construir el proceso en memoria.
Más informacion sobre el formato ELF elf format
Un programa es algo _sin vida_, un conjunto de instrucciones y datos que esperan en algún lugar del disco para saltar a la acción!!!
Y el Sistema Operativo es quien toma ese puñado de bytes y es el SO que transforma ese programa en algo útil, mediante el Kernel.
Uno nunca tiene que ser consciente si la CPU está disponible, etc. sólo ejecuta el programa.
En este punto se tiene un programa capaz de ser ejecutado por una computadora, es función del sistema operativo hacer que este se ejecute, para ello existe el concepto de proceso.
El Sistema Operativo más precisamente el Kernel se encarga de:
Cargar instrucciones y Datos de un programa ejecutable en memoria.
Crear el Stack y el Heap [^2]
Transferir el Control al programa
Proteger al SO y al Programa
El Proceso¶
“Un proceso es la ejecución de un programa de aplicación con derechos restringidos; el proceso es la abstracción que provee el Kernel del sistema operativo para la ejecución protegida”- [DAH]
“Es simplemente un programa que se está ejecutando en un instante dado” - [ARP]
“Un Proceso es la instancia de un programa en ejecución” - [VAH]
“Un proceso es un programa en medio de su ejecución” - [LOV]
Por supuesto que no está más lejos de la verdad, decir que un proceso es sólo un programa en ejecución. Un proceso incluye:
Los Archivos abiertos
las señales(signals) pendientes
Datos internos del kernel
El estado completo del procesador
Un espacio de direcciones de memoria
- Uno o más hilos de Ejecución. Cada thread contiene
Un único contador de programa
Un Stack
Un Conjunto de Registros
Una sección de datos globales
La Virtualización¶
Note
Crear una abstracción que haga que un dispositivo de hardware sea mucho más fácil de utilizar .
Particularmente el concepto de proceso es el más importante de todos los conceptos que se ven en sistemas operativos. En los sistemas operativos modernos proporciona dos tipos de virtualización:
Virtualización de memoria
Virtualizacion de procesador
Virtualización de Memoria¶
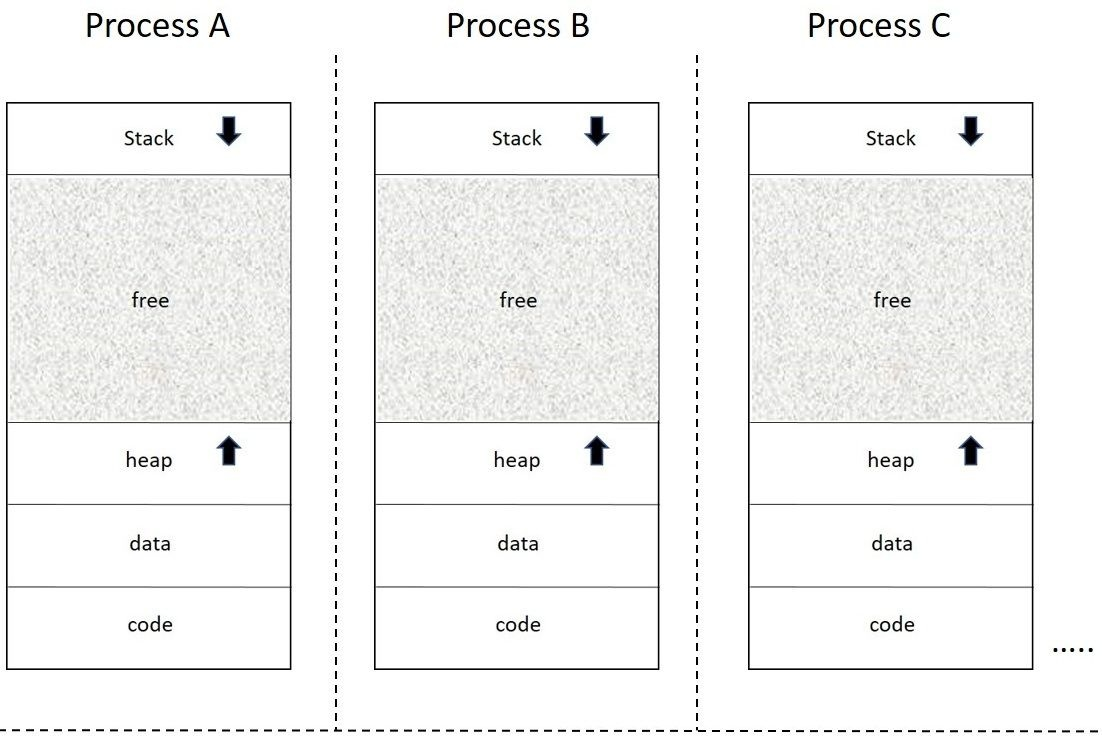
La virtualización de memoria le hace creer al proceso que este tiene toda la memoria disponible para ser reservada y usada como si este estuviera siendo ejecutado sólo en la computadora (ilusión). Todos los procesos en Linux, está dividido en 4 segmentos:
Text: Instrucciones del Programa.
Data: Variables Globales (extern o static en C)
Heap: Memoria Dinámica Alocable
Stack: Variable Locales y trace de llamadas
Todas estas secciones pertenecientes a un proceso se denominan espacio de direcciones del proceso.
Para ejecutar un programa el sistema operativo:
Copia las instrucciones en la sección .code y los datos en la sección .data, desde el programa ejecutable residente en disco hacia la memoria física,
Además el sistema operativo setea una región de memoria llamada execution stack (.stack), que mantiene el estado de las variables locales durante las llamadas a los procedimientos.
EL sistema operativo también setea una región de memoria llamada heap, destinada a alojar cualquier estructura de datos alocada en forma dinámica que el programa pueda necesitar.
#include <stdio.h>
#include <stdlib.h>
char globBuf[65536]; /* Uninitialized data segment */
int primes[] = { 2, 3, 5, 7 }; /* Initialized data segment */
static int
square(int x) /* Allocated in frame for square() */
{
int result; /* Allocated in frame for square() */
result = x * x;
return result; /* Return value passed via register */
}
static void
doCalc(int val) /* Allocated in frame for doCalc() */
{
printf("The square of %d is %d\n", val, square(val));
if (val < 1000) {
int t; /* Allocated in frame for doCalc() */
t = val * val * val;
printf("The cube of %d is %d\n", val, t);
}
}
int
main(int argc, char *argv[]) /* Allocated in frame for main() */
{
static int key = 9973; /* Initialized data segment */
static char mbuf[10240000]; /* Uninitialized data segment */
char *p; /* Allocated in frame for main() */
p = malloc(1024); /* Points to memory in heap segment */
doCalc(key);
exit(EXIT_SUCCESS);
}
Protección de Memoria¶
Para que un proceso se ejecute tiene que estar residente en memoria, pero a su vez el sistema operativo tiene que estar residente en memoria.
El proceso tiene que estar en memoria para poder ejecutarse.
Mientras que:
El sistema operativo tiene que estar ahí para:
iniciar la ejecución del programa
manejar las interrupciones
y/o atender las systems call.
Es más, otros procesos podrían estar simultáneamente en memoria para poder compartir la memoria de forma segura, para ello el sistema operativo tiene que poder configurar el hardware de forma tal que cada proceso pueda leer y escribir solo su propia memoria (No la memoria del sistema operativo tampoco la de otros procesos. Ya que sino el proceso en cuestión podría incluso modificar al Kernel del sistema operativo. Para ello el Hardware debe proveer un mecanismo de protección de memoria, (que se verán detalladamente mas adelante).
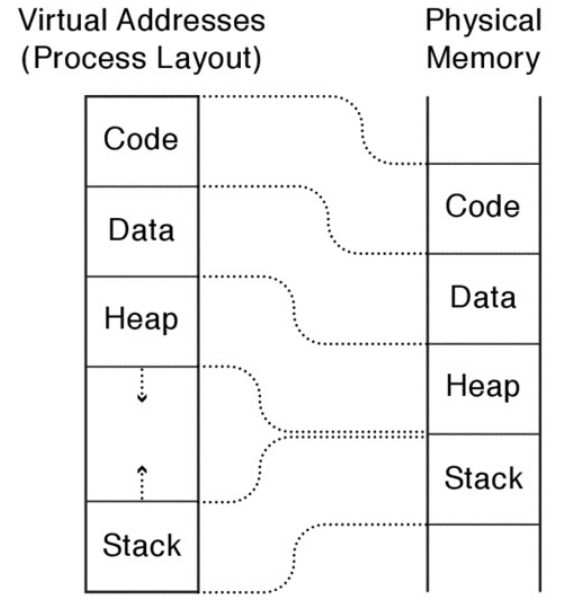
Uno de estos mecanismos es denominado Memoria Virtual, la memoria virtual es una asbtracción por al cual la memoria física puede ser compartida por diversos procesos.
Un componente clave de la memoria virtual son las direcciones virtuales, con las direcciones virtuales, para cada proceso su memoria inicia en el mismo lugar, la dirección 0.
Cada proceso piensa que tiene toda la memoria de la computadora para si mismo, si bien obviamente esto en la realidad no sucede. El hardware traduce la dirección virtual a una dirección física de memoria.
Traducción de Direcciones¶
Se traduce una Dirección Virtual (emitida por la CPU) en una Dirección Física (la memoria). Este mapeo se realiza por hardware, más específicamente por Memory Management Unit (MMU).

Virtualización de Procesador¶
La virtualización de procesamiento es la forma de virtualización más primitiva, consiste en dar la ilusión de la existencia de un único procesador para cualquier programa que requiera de su uso. De esta forma, se provee:
Simplicidad en la programación
Cada proceso cree que tiene toda la CPU.
Cada proceso cree que todos los dispositivos le pertenecen.
Distintos dispositivos parecen tener el mismo nivel de interfaces.
Las interfaces con los dispositivos son más potentes que el bare metal.
Aislamiento frente a Fallas:
Los procesos no pueden directamente afectar a otros procesos.
Los errores no colapsan toda la máquina.
¿Cómo se provee la ilusión de tener varios CPUs?
El SO crea esta ilusión mediante la virtualización de la CPU a través del kernel.
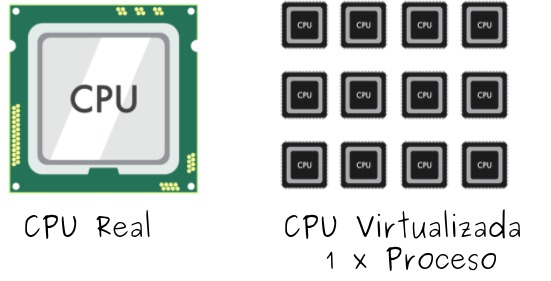
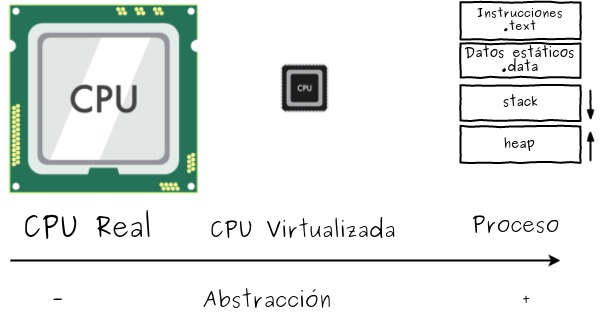
Viéndolo desde el punto de vista de la abstracción y virtualización:
Un ejemplo sencillo virtualización de proceso
#include <stdio.h>
#include <stdlib.h>
#include "../common.h"
int main(int argc, char *argv[])
{
if (argc != 2) {
fprintf(stderr, "usage: cpu <string>\n");
exit(1);
}
char *str = argv[1];
while (1) {
printf("%s\n", str);
Spin(1);
}
return 0;
}
muestra que si bien la computadora está ejecutando mas de un proceso todos creen que la CPU (Unidad Central de Procesamiento) está disponible en forma exclusiva para ese único proceso.
Entonces:¶
“un proceso es básicamente una abstracción de un programa en ejecución.”
Se ha de tener en cuenta que el Kernel en sí mismo también es un proceso y que la abstracción del proceso provee ejecución, aislamiento y protección. Estos tres conceptos pueden merecer varios capítulos de un libro. El sistema operativo lleva la contabilidad de todos los procesos que se están ejecutando en la computadora mediante la utilización de una estructura llamada Process Control Block o PCB. La PCB almacena toda la información que un sistema operativo debe conocer sobre un proceso en particular:
Donde se encuentra almacenado en memoria.
Donde la imagen ejecutable esta en el disco.
Que usuario solicito su ejecución.
Que privilegios tiene ese proceso.
El Proceso: por dentro¶
Note
El concepto de proceso es la más bella de las abstracciones que los constructores de sistemas operativos han creado.
La idea general detrás de la abstracción es la de cómo virtualizar una CPU o procesamiento, es decir cómo hacer para que un único procesador actúe como tal para varios programas que requieren ser ejecutados utilizando el mismo hardware, en este caso un microprocesador.
Un Proceso necesita permisos del Kernel del SO para:
Acceder a memoria perteneciente a otro proceso.
Antes de escribir o leer en el disco.
Antes de cambiar algún seteo del hardware del equipo.
Antes de enviar información a otro proceso.
Pero además el S.O. crea la ilusión de la existencia de varios cientos o miles de procesadores, cuando en realidad tiene uno solo, mediante la virtualización de la CPU …. ¿Cómo? Con el concepto de Proceso que es la ilusión creada para la virtualización de la CPU. El Kernel del S.O. provee esa abstracción.
Arquitectura de Von Newman: Instruction Fetch¶
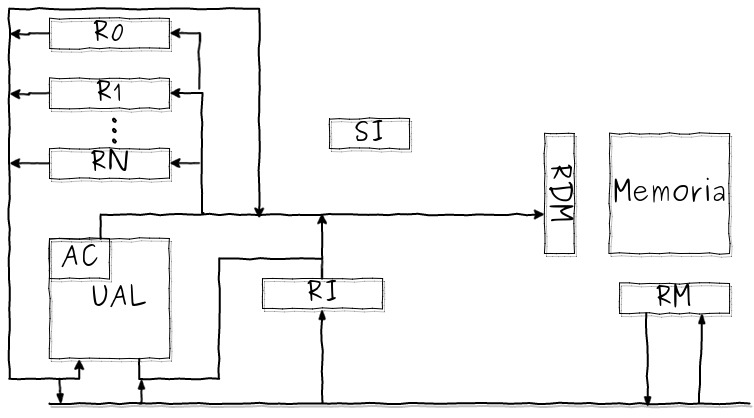
El ciclo de una instrucción en una arquitectura de Von Newman:
Obtener la instrucción (Fetch)
Decodificar la instrucción (Decode)
Ejecutar la instrucción (Execute)
CP = Próxima Instrucción
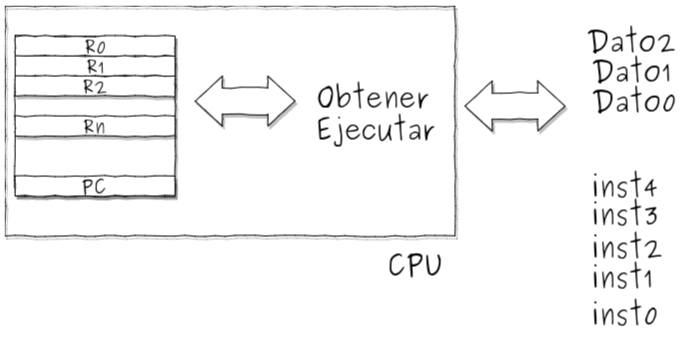
El API de Procesos:¶
Que debe incluir cualquier interfaz de un SO:
Creación (Create) [^3]: todo sistema operativo debe incluir una forma de crear un nuevo proceso.
Destrucción(Destroy) [^4]: así como existe una interface para crear un proceso debe existir una interface para destruirlo por la fuerza.
Espera (wait): A veces es útil esperar a que un proceso termine su ejecución por ende algún tipo de interface de espera debe ser provista.
Control Vario (Miscellaneous Control): Además de esperar o matar a un proceso otros tipos de operaciones deben poder realizarse. Por ejemplo, suspender su ejecución por un tiempo y luego reanudarla.
Estado (Status) : Tiene que existir una forma de saber sobre la situación del proceso y su estado. Cuánto hace que se está ejecutando, en que estado se encuentra, etc.
Estas son las acciones básicas que todo SO debe proveer sobre la abstracción de la CPU.
El API de Procesos de Unix-like, System Calls:¶
El modelo de creación de procesos de unix es una característica interesante para estudiar. Un proceso en unix sólo puede ser creado por otro proceso. el proceso creador se denomina proceso padre y el proceso creado se denomina proceso hijo. Obviamente esto suele parecer extraño ya que la pregunta que siempre surge es: ¿Quién crea el primer proceso? … ¿Quien nació antes el huevo o la gallina?.
El Contexto de un Proceso:¶
Cada proceso tiene un contexto bien definido que comprende la información toda la información necesaria para describir completamente al mismo [VAH p.26].
- El contexto de un proceso consiste:
User Address Space: normalmente está dividido en varias áreas: text, data, stack y heap,
Control Information: el kernerl utiliza dos estructuras principales para mantener información de control de un proceso- la u area y la estructura proc. Cada proceso ademas tiene su propio kernel stack y mapas de traduccion de ditrecciones.
Credentials: Las credenciales del proceso incluyen los groups IDs y user id, asociados con el.
Variables de entorno: son un conjunto de strings del formaro variable=valor que son heredadas del [proceso padre.
- Hardware Context: Esto contine el contenido de los registros de proposito general, y de un conjunto especial de registros del system:
El Program Counter (PC)
El Stack Pointer (SP)
El Processor Status Word (PWD)
Memory Management Registers
Los Registros de la Unidad de Punto Flotante.
En forma resumida, el contexto de un proceso consiste según [BCH] en la unión de user-level context, register context y system level context:
User-level Context: consiste en las secciones que forman parte de Virtual Address Space del proceso.
text,
data,
stack,
heap
Register Context: El contexto de registro consiste de los siguientes componentes:
- Contador de Programa
Registro de Estado del Procesador (PS)
Stack Pointer
Los Registro de Proposito General
System-level Context: Consiste en :
La entrada en la Process Table Entry
La u area
La Process Region Entry, Region Table y Page Table que definen el mapeo de la memoria virtual vs memoria física del proceso.
En C eso se traduce a:
// the registers xv6 will save and restore
// to stop and subsequently restart a process
struct context
{
int eip;
int esp;
int ebx;
int ecx;
int edx;
int esi;
int edi;
int ebp;
};
// the different states a process can be in
enum proc_state { UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
// the information xv6 tracks about each process
// including its register context and state
struct proc {
char *mem; // Start of process memory
uint sz; // Size of process memory
char *kstack; // Bottom of kernel stack
// for this process
enum proc_state state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
struct context context; // Switch here to run process
struct trapframe *tf; // Trap frame for the
// current interrupt
};
La U Area y estructura Proc¶
La información de control sobre un proceso es mantenida en dos per process data structures. Estas estructuras dependen de la implementación del kernel mismo, la proc structure es una entrada en una tabla conocida como process table.
La U area o user area es parte del espacio del proceso, se mapea y es visible por el proceso solo cuando este esta siendo ejecutado. La user area contiene información que solo es necesario acceder cuando el proceso se está ejecutando. Por el contrario la proc strucure posee información necesaria incluso cuando el proceso no se esta ejecutando.
Contenido de la user area <arch/x86/include/asm/user.h>:
La Process Control Block - guarda el hardware context cuando el proceso no se esta ejecutando
Un puntero a la proc structure del proceso
El UID y GID real
Argumentos para, y valores de retorno o errores hacia, la system call actual
Manejadores de Señales
Información sobre las areas de memoria text,data, stack, heap y otra información.
La tabla de descriptores de archivos abiertos (Open File dscriptor Table).
Un puntero al directorio actual
Datos estadísticos del uso de la cpu, información de perfilado, uso de disco y limites de recursos.
Contenidos de la estructura Proc:
Identificación: cada proceso tiene un identificador único o process ID (PID) y ademas perteneces a un determinado grupo de procesos.
Ubicación del mapa de direcciones del Kerner del u area del proceso.
Estado actual del proceso
Un puntero hacia el siguiente proceso en el planificador y al anterior.
Prioridad
Información para el manejo de señales.
Información para la administración de memoria.
El linux la proc structure se conoce como la task structure
El API resumida:¶
fork(): Crea un proceso y devuelve su id.
exit(): Termina el proceso actual.
wait(): Espera por un proceso hijo.
kill(pid): Termina el proceso cuyo pid es el parámetro.
getpid(): Devuelve el pid del proceso actual.
exec(filename, argv): Carga un archivo y lo ejecuta.
sbrk(n): Crece la memoria del proceso en n bytes.
System Call getpid() y getppid()¶
Esta system call _getpid()_ permite determinar el PID (Process IDentification).
Originalmente en UNIX el PID es un número positivo hasta 32,768, una vez alcanzado ese numero se resetea a 300 y se vuelven a asignar esos valores nuevamente. Esto pasaba en Linux, hasta la versión 2.6 del kernel, en la cual dependiendo de la plataforma ese valor es ajustable, dependiendo de la plataforma [^1]:
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);
La versión getppid() devuelve el PID del proceso padre del proceso.
Para validar esto se puede ejecutar el comando pstree.
Creación de un Proceso¶
La única forma de que un usuario cree un proceso en el sistema operativo _UNIX_ es llamando a la system call _fork_.
El proceso que invoca a _fork_ es llamado proceso padre, el nuevo proceso creado es llamado hijo.
- ¿Que hace fork?:
Crea y asigna una nueva entrada en la Process Table para el nuevo proceso.
Asigna un número de ID único al proceso hijo.
Crea una copia lógica del contexto del proceso padre, algunas de esas partes pueden ser compartidas como la sección text
Realiza ciertas operaciones de I/O.
Devuelve el número de ID del hijo al proceso padre [^3], y un 0 al proceso hijo
¿Qué hace _fork()_, el algoritmo:¶
La implementación de esta system call no es para nada trivial ya que cuando el proceso hijo inicia inicia a ejecutarse parece hacerlo casi en el aire:
chequear que haya recursos en el kernel;
obtener una entrada libre de la Process Table, como un PID único;
chequear que el usuario no esté ejecutando demasiados procesos;
macar al proceso hijo en estado “siendo creado”;
copiar los datos de la entrada en la Process Table del padre a la del hijo;
incrementar el contador del current directoty inode;
incrementar el contador de archivos abiertos en la File Table;
hacer una copia del contexto del padre en memoria;
- crear un contexto a nivel sistema falso para el hijo;
el contexto falso contiene datos para que el hijo se reconozca a sí mismo
y para que tenga un punto de inicio cuando el planificador lo haga ejecutarse;
if(el proceso en ejecución es el padre)
{
cambiar el estado del hijo a "ready to run";
return ( ID del hijo);
}
else /* se esta ejecutando el hijo */
{
inicializar algunas cosas;
return 0;
}
Aspectos Curiosos de fork()¶
Una llamada dos valores de retorno: fork se llama una vez desde el proceso padre, pero devuelve dos valores uno valor al proceso padre y otro valor al proceso hijo.
Ejecución concurrente: ambos procesos se ejecutan en forma concurrente por lo cual no hay determinismo en el orden de ejecución.
Address space duplicados pero separados: si se pudieran para el padre y el hijo después de la ejecución de fork, se vería que el addres space de cada proceso son idénticos.
Archivos compartidos la user file descriptor table es heredada con todos sus archivos en el mismo estado.
Manejo de errores en fork¶
La system call _fork()_ devuelve:
el valor 0 al proceso hijo,
el PID del hijo al proceso padre, o
un valor negativo si hubo algún error
if ((pid = fork()) < 0) {
fprintf(stderr, "fork error: %s\n", strerror(errno));
exit(0);
}
Ejemplo del uso del fork() obtenido del [ARP]:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
printf("hello world (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0)
{// fork failed; exit
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) { // child (new process)
printf("hello, I am child (pid:%d)\n", (int) getpid());
}
else {
// parent goes down this path (main)
printf("hello, I am parent of %d (pid:%d)\n", rc, (int) getpid());
}
return 0;
}
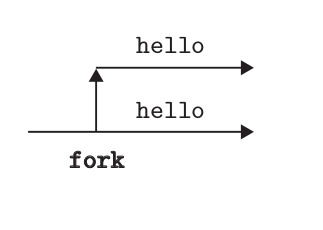
Algunas Notas: * El proceso creado es casi un copia exacta del proceso padre [^2]. * Un punto destacable es que el nuevo proceso no comienza su ejecución en main(), sino justo después de la ejecución de fork(). * Si bien el nuevo proceso es exactamente igual al padre, la diferencia entre ambos el el valor de retorno de fork(). * Por último, el output no es determinístico, entra en juego el planificador.
Más ejemplos:¶
fock() más complejo:¶
Ejemplos más complejos con fork()
#include<stdio.h>
#include <stdlib.h>
#include <unistd.h>
pid_t Fork(){
pid_t pid;
pid = fork();
if (pid < 0) { /* error */
perror(" Error de fork");
exit(-1);
}
return pid;
}
int main()
{
Fork();
Fork();
printf("Hola! padre : %d -> mi PID: %d\n",getppid(),getpid());
exit(0);
}
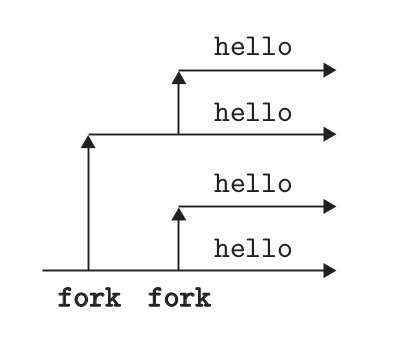
#include<stdio.h>
#include <stdlib.h>
#include <unistd.h>
pid_t Fork(){
pid_t pid;
pid = fork();
if (pid < 0) { /* error */
perror(" Error de fork");
exit(-1);
}
return pid;
}
int main()
{
Fork();
Fork();
Fork();
printf("Hola! padre : %d PID es: %d\n",getppid(),getpid());
exit(0);
}
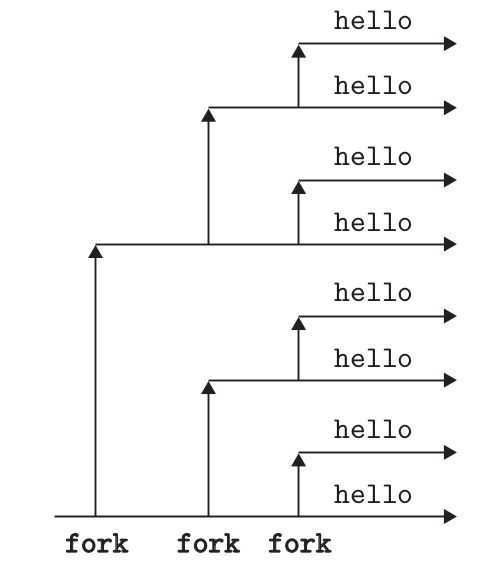
System Call _exit()¶
Generalmente un proceso tiene dos formas de terminar:
La anormal: a través de recibir una señal cuya acción por defecto es terminar el programa.
La normal: a través de invocar a la system call exit()
Esta system call generalmente no es utilizada, en su lugar se utiliza exit() de la biblioteca estándar de C.
Que hace exit() , el algoritmo:¶
Ignora todas las signals.
Cierra todos los archivos abiertos
En consecuencia se liberan todos los locks mantenidos por este proceso sobre esos archivos
Libera el directorio actual
Los segmentos de memoria compartida del procesos se separan
los contadores de los semáforos son actualizados
Libera todas las secciones y memoria asociada al proceso
Registra información sobre el proceso (accounting record)
Pone el estado del proceso en “zombie”
Le asigna el parent PID de los procesos hijos al PID de init
le manda una signal o señal de muerte al proceso padre
context switch
#include <stdlib.h>
void exit(int status);
Esta función de la biblioteca estándar de C :
llama a los Exit Handler que son dos funciones llamadas on_exit() y atexit()
los streams de stdio son flusheados ( buffer–>disco )
se llama a la system call _exit().
System Call wait()¶
Un proceso puede sincronizar su ejecución con la finalización de un proceso hijo mediante la ejecución de wait()
En ciertos casos el proceso padre necesita esperar que el proceso hijo realice cierta tarea para continuar con su ejecución.
Para ello existe la system call wait() que retrasa la ejecución del proceso padre hasta que el proceso hijo termine su ejecución.
Ejemplo de fork() y wait ():
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t pid;
pid = fork();
if (pid == 0) { /* Hijo */
printf(" Soy Luke .... mi pid es : %d\n", getpid() );
exit(0);
}
/* Padre */
int status;
pid_t p= wait(&status);
printf(" Mi pid es%d .... Luke soy tu padre!!!!\n", getpid());
return 0;
}
System Call exec()¶
Y a continuación se verá como hacer que el nuevo proceso creado no esté relacionado con el proceso padre. Para ello se utiliza la system call excec().
Existen 6 variantes de exec(): execl(), execle(), execlp(), execv() y execcvp().
#include <unistd.h>
int execve(const char *filename, const char *argv[], const char *envp[]);
La system call _exec()_ invoca a otro programa, sobreponiendo el espacio de memoria del proceso con el programa ejecutable.
¿Qué hace exec?¶
obtiene el inodo del programa;
verifica si el archivo es ejecutable y si el usuario iene los permisos para ejecutarlo;
lee el header del archivo;
copia los parámetros del exec del viejo address space al system space;
para (cada región asociada al proceso) las des-asocia
para (cada región especificada en el módulo ejecutable) {
alloca espacio para las nueva región; asocia (attach) la región; carga la región en la memoria;
}
copia los parámetros del exec en la nueva región o sección stack;
hace cierta magia;
inicializa a modo usuario;
libera el inodo;
El ejemplo de a continuación puede verse en el [ARP], en el cual se usa fork(), wait() y execvp():
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/wait.h>
int
main(int argc, char *argv[]){
printf("hello world (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0){
// fork failed; exit
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
// child (new process)
printf("hello, I am child (pid:%d)\n", (int) getpid());
char *myArgs[3];
myArgs[0]=strdup("wc"); // programa wc
myArgs[1]=strdup("proceso2.c"); // arg: programa a ser contado
myArgs[2]=NULL; // marca el fin del arreglo
execvp(myArgs[0],myArgs);
printf("Esto no deberia imprimirse pues es totalmente reemplazado");
} else {
// parent goes down this path (main)
int wc = wait(NULL);
printf("hello, I am parent of %d (wc:%d) (pid:%d)\n",rc, wc, (int) getpid());
} }
[^1]: 32-bits 32,768 , 64-bits 2^22. [^2]: solo difieren en el PID. [^3]: esto implica que el padre sabe quien es su hijo.
System call brk()¶
Para entender esta system call es necesario entender el layout o estructura real de la memoria de un proceso en linux, [KER] (cap 6, pag.119):
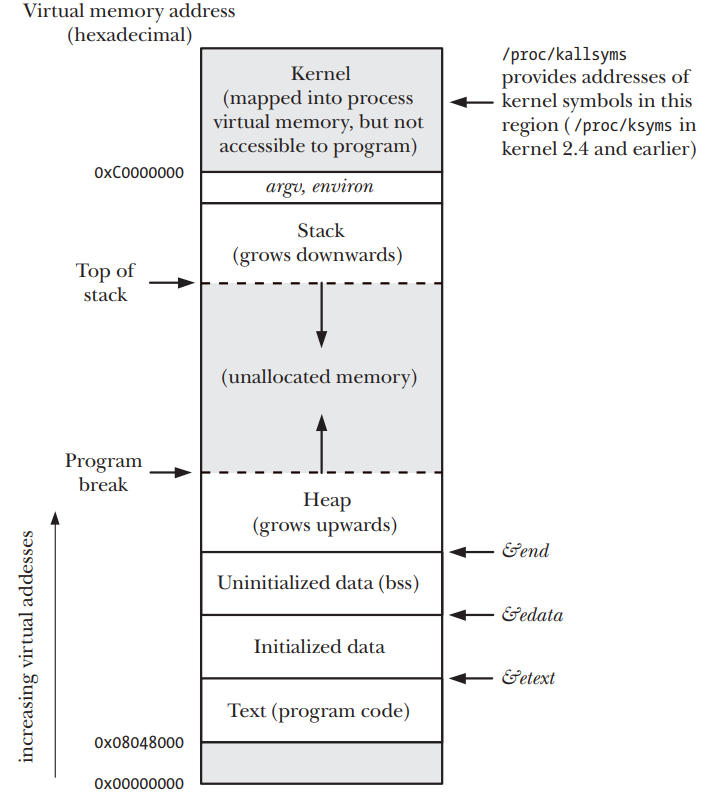
Como puede apreciarse el final del heap se denomina break. El heap aumenta hacia direcciones altas, crece hacia arriba (grows upwards) y el stack se crece hacia direcciones bajas (grows downwards).
Un proceso puede reservar memoria para sí mismo incrementando el tamaño del heap, recordar que el limite actual del heap se denomina break. Para reservar memoria, un programa en C normalmente utiliza la familia de funciones malloc() (man 3 malloc). Esta función está basada en la system call brk().
Note
Redimensionar el heap (reservando o liberando memoria) es tan simple como pedirle al kerner que ajuste su idea de donde el break del proceso está.
Inicialmente el break* del programa está ubicado justo en el final de datos no inicializados. Despues que brk() se ejecuta, el break es incrementado, el proceso puede acceder a cualquier memoria en la nueva área reservada, pero no accede directamente a la memoria física. Esto se realiza automáticamente por el kernel en el primer intento del proceso en acceder al área reservada.
#include <unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);
El parámetro de sbrk() es la dirección exacta donde el nuevo break debe estar. Por otro lado en sbrk() se pasa el incremento al cual se le sumará al viejo break para setear el nuevo break. Si se ejecuta sbrk(0) se obtiene la dirección del break actual [KER] cap 7.
Metamorfosis: de programa a proceso¶
El SO debe cargar el programa, su código y cualquier dato estático en la memoria. Los programas residen en disco en algún formato ejecutable, en Linux este formato es elf.
En los SO antiguos esto se realizaba de forma abrupta (eagerly) instrucciones y datos.
En los SO modernos se realiza de forma perezosa (lazily), cargando lo que se necesite según se necesite.
Se crea la pila de ejecución (Execution Stack) en base a reservar cierta cantidad de memoria, la misma se inicializa por ejemplo si usamos C con argv y argc del main().
Se crea el Heap en base a reservar otra cierta cantidad de memoria, el Heap sirve para la reserva de memoria dinámica, en C se crea y se destruyen estructuras memoria dinámica con malloc() y free().
- Por último el SO realizará otras operaciones. Varias de ellas relacionadas con operaciones de Entrada y Salida de Datos.
Por ejemplo, en los SO Unix-like cada proceso posee por defecto 3 descriptores de archivos abiertos:
Standard Input
Standard Output
Standard Error
Una vez que todo lo anterior sucedió, un última cosa sucede, se setea el punto de entrada (entry point) de ejecución de las instrucciones del programa en el main().
Estados de un Proceso¶
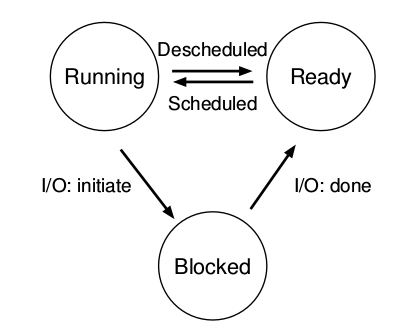
- En una visión simplificada un proceso puede encontrarse en los siguientes estados:
Corriendo (Running): el proceso se encuentra corriendo en un procesador. Está ejecutando instrucciones.
Listo (Ready): en este estado el proceso está listo para correr pero por algún motivo el SO ha decidido no ejecutarlo por el momento.
Bloqueado (Blocked): en este estado el proceso ha ejecutado algún tipo de operación que hace que éste no esté listo para ejecutarse hasta que algún evento suceda.
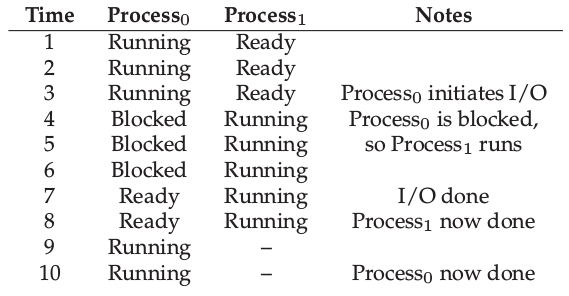
Dos Procesos solo con Cómputo, uso de CPU¶

Dos Procesos con Cómputo y Entrada y Salida, uso de CPU¶
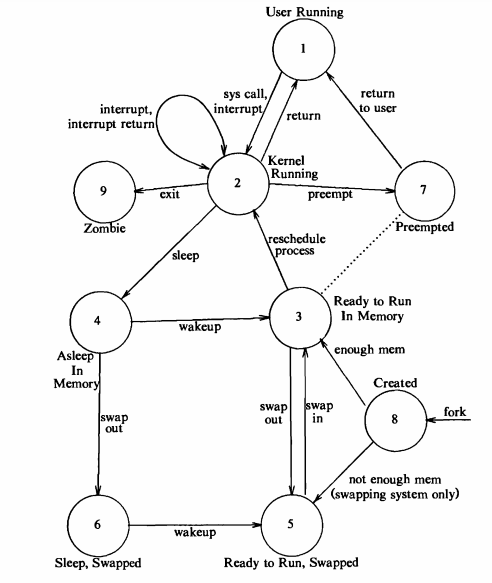
Estados en Unix System V:¶
Corriendo User Mode(Running User Mode): El proceso se encuentra corriendo en un procesador. Está ejecutando instrucciones.
Corriendo kernel Mode(Running Kernel Mode): d
Listo para Corre en Memoria (Ready to Run on Memory): En este estado el proceso está listo para correr pero por algún motivo el SO ha decidido no ejecutarlo por el momento.
Durmiendo en Memoria (Asleep In Memory) : El proceso está bloqueado en memoria.
Listo para Correr pero Swapeado (Ready to Run but wapped): El proceso está bloqueado en memoria secundaria.
Durmiendo en Memoria Secundaria (Asleep Swapped): El proceso se encuentra bloqueado en memoria secundaria.
Preempt(Preempt): Es igual a 1 pero un proceso que pasó antes por Kernel mode solo puede pasar a preentive.
Creado (Created): El proceso está recién creado y en un estado de transición.
Zombie (Zombie): El proceso ejecutó la S.C. exit(), ya no existe más, lo único que queda es el exit state.
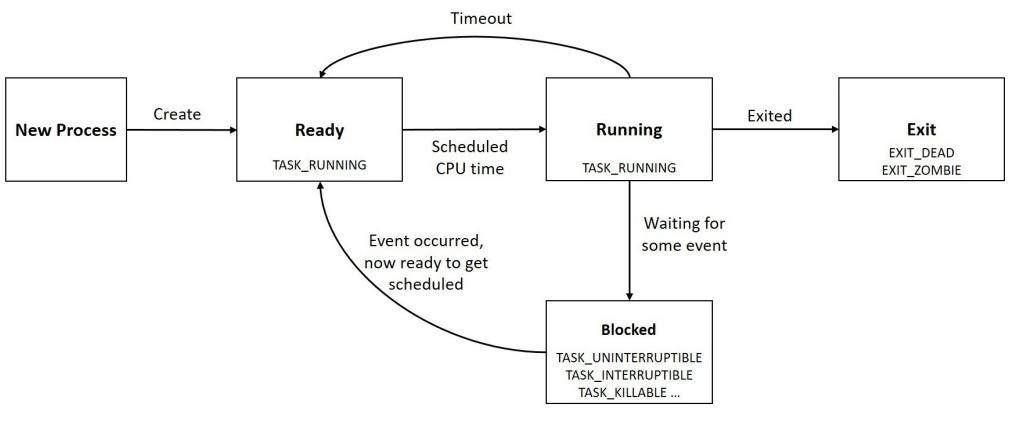
Estados en Linux¶
Dado que en Linux los procesos son denominodos tasks los estados de una task pueden ser:
TASK_RUNNING (0): El proceso está o ejecutándose o peleando por CPU en la cola de run del planificador.
TASK_INTERRUPTIBLE (1): El proceso se encuentra en un estado de espera interrumpible; este queda en este estado hasta que la condicion de espera eventualmente sea verdadera, por ejemplo un dispositivo de I/O esta listo para ser utilizado, comienza de su time slice, etc. Mientras el proceso está en este estado, cualquier señal (signal) generada para el proceso es entregada al mismo, causando que este se despierte antes que la condición de espera se cumpla.
TASK_KILLABLE: este estado es similar al TASK_INTERRUPTIBLE, con la excepción que las interrupciones pueden ocurrir en fatal signals.
TASK_UNINTERRUTPIBLE (2): El proceso está en un estado de ininterrupción similar al anterior pero no podrá ser despertado por las señales que le lleguen. Este estado es raramente utilizado.
TASK_ STOPPED (4): El proceso recibió una señal de STOP. Volverá a running cuando reciba la señal para continuar (SIGCONT).
TASK_TRACED (8): Un proceso se dice que esta en estado de trace, cuando está siendo revisado probablemente por un debbuger.
EXIT_ZOMBIE (32): El proceso está terminado, pero sus recursos aún no han sido solicitados.
EXIT_DEAD (16): El proceso Hijo ha terminado y todos los recursos que este mantenía para sí se han liberado, el padre posteriormente obtiene el estado de salida del hijo usando wait.
Desde el Kernel de Linux¶
El kernel almacena la lista de procesos en una lista circular doblemente enlazada llamada task list
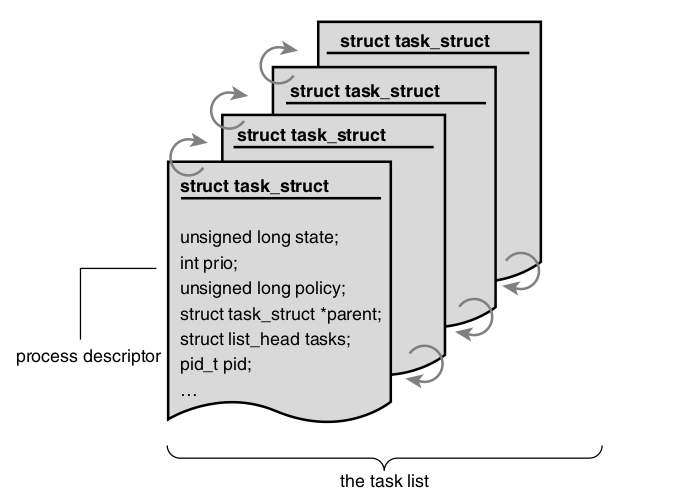
Cada elemento de la task list es un descriptor de proceso (process descriptor) del tipo task_struct, definida en in <linux/sched.h>.
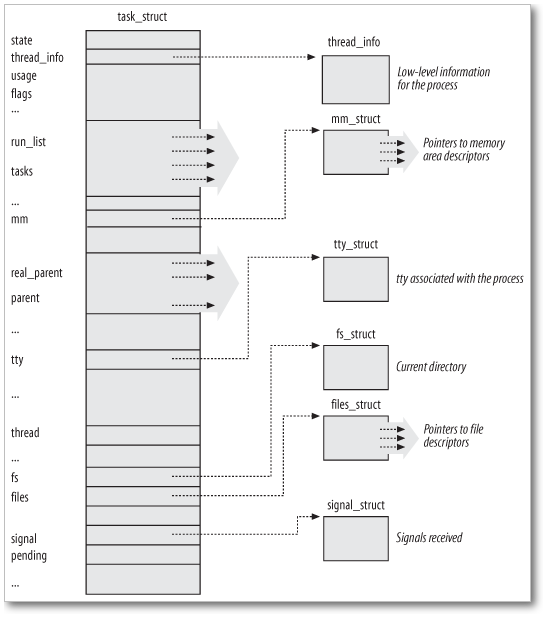
Esta estructura es relativamente pesada, unos 1.7 Kb en 32-bit [^7]_.
Los procesos se identifican en linux al igual que en unix via el PID (process identification), este es un valor numérico de 0 a 32768, si bien este puede ser cambiado (<linux/threads.h>) hasta 4 millones. Puede verse ejecutando >$ cat /proc/sys/kernel/pid_max.
Normalmente, se asignan a partir del número 500.
..[^1]: Algo estático, sin vida. ..[^3]:cuando se ejecuta un comando en el shell o se hace doble click en un icono de una aplicación este comando debe ser ejecutado ..[^4]: Si bien la mayoria de los procesos se inician y se destruyen por sí mismo ..[^2]: ¿Qué se guarda en el heap y en el stack? .. [^4]: espacio de usuario. .. [^5]: En x86, el tamaño de la pila es configurable en tiempo de compilación y puede ser de 4 KB u 8 KB. .. [^6]: Symmetrical Multiprocessing .. [^7]: Bastante pequeña si se considera que possee todos los datos requeridos por el kernel sobre un proceso